前言
Spark Streaming 是将实时数据流按时间分段后,当作小的批处理数据去计算。那么 Flink 则相反,一开始就是按照流处理计算去设计的。当把从文件系统(HDFS)中读入的数据也当做数据流看待,他就变成批处理系统了。
使用-dataflow模型
public class KafkaExample {
public static void main(String[] args) throws Exception {
// parse input arguments
final ParameterTool parameterTool = ParameterTool.fromArgs(args);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setRestartStrategy(RestartStrategies.fixedDelayRestart(4, 10000));
env.enableCheckpointing(5000); // create a checkpoint every 5 seconds
env.getConfig().setGlobalJobParameters(parameterTool); // make parameters available in the web interface
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStream<KafkaEvent> input = env .addSource(
new FlinkKafkaConsumer<>(
parameterTool.getRequired("input-topic"),
new KafkaEventSchema(),
parameterTool.getProperties())
.assignTimestampsAndWatermarks(new CustomWatermarkExtractor()))
.keyBy("word")
.map(new RollingAdditionMapper())
.shuffle();
input.addSink(
new FlinkKafkaProducer<>(
parameterTool.getRequired("output-topic"),
new KeyedSerializationSchemaWrapper<>(new KafkaEventSchema()),
parameterTool.getProperties(),
FlinkKafkaProducer.Semantic.EXACTLY_ONCE));
env.execute("Modern Kafka Example");
}
}
理论基础来自谷歌论文 《The dataflow model:A pracitical approach to balancing correctness,latency, and cost in massive-scale,unbounded,out-of-order data processing》
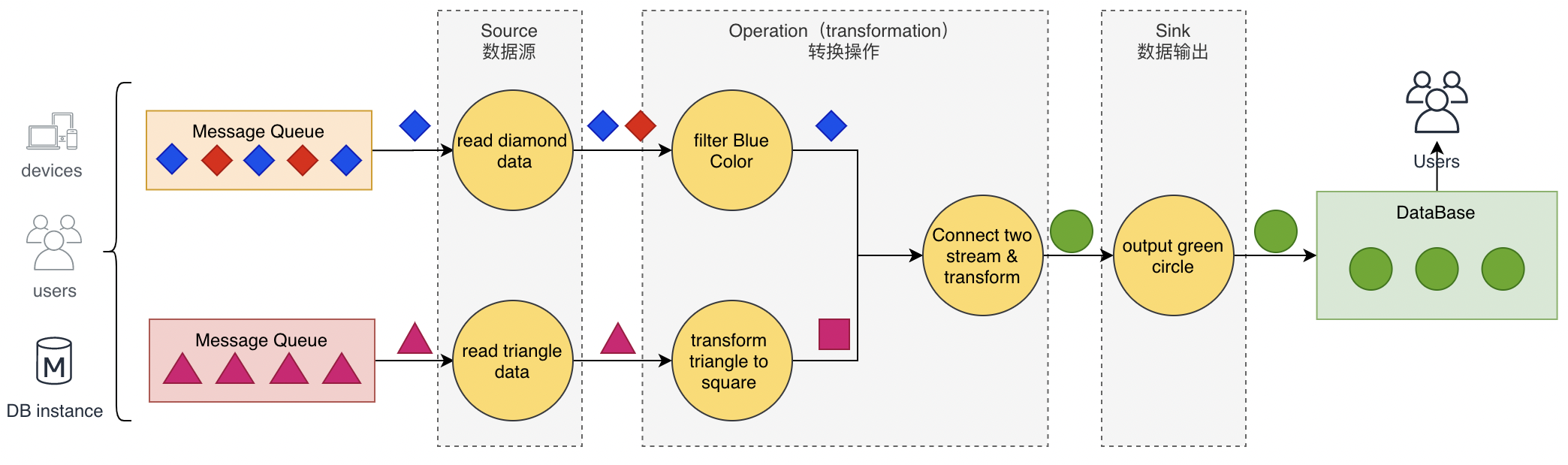
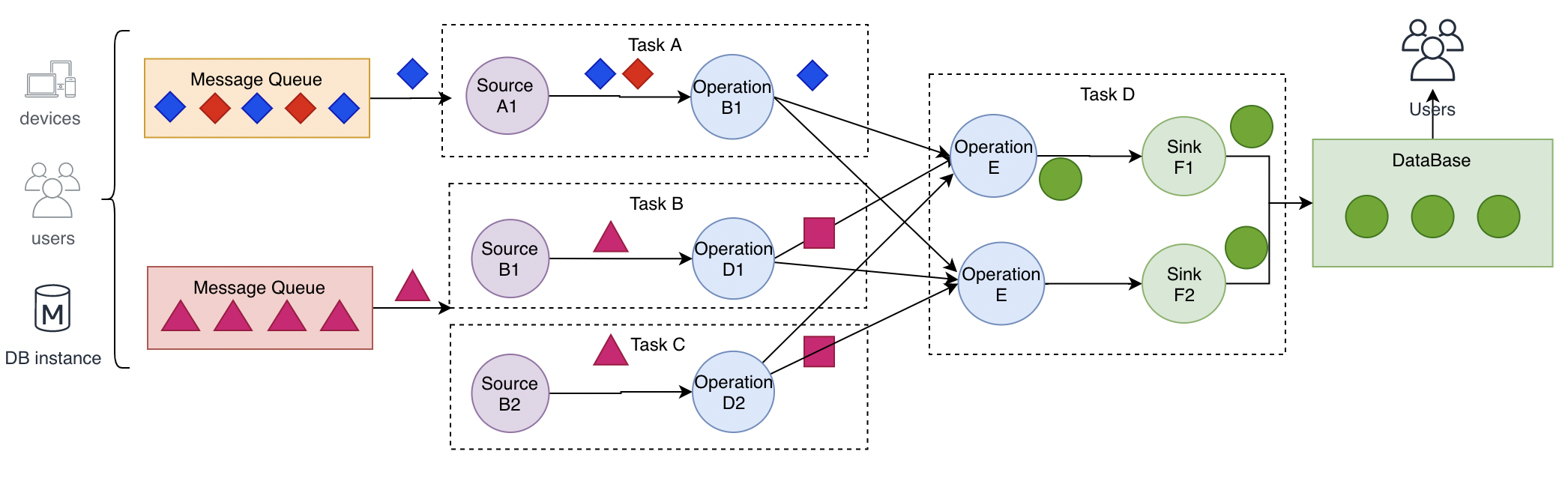
- 数据从上一个Operation节点直接Push到下一个Operation节点。
- 各节点可以分布在不同的Task线程中运行,数据在Operation之间传递。
- 具有Shuffle过程,数据从上游Operation push 到下游Operation,不像MapReduce模型,Reduce从Map端拉取数据。
- 实现框架有ApacheStorm和ApacheFlink以及ApacheBeam。
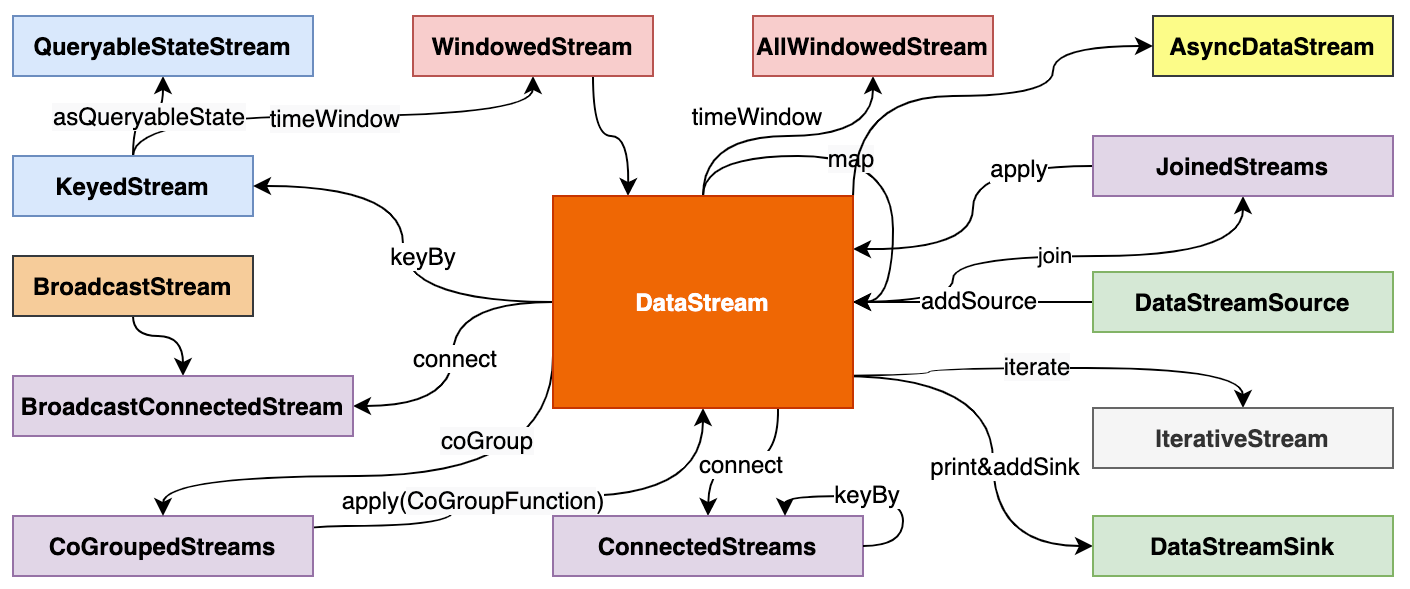
DataStream API
- source
- sink
- 转换操作
- 基于单条记录filter/map
- 基于窗口 window
- 多流合并 union join connect
- 单流切分 split
-
DataStream 之间的转换
为什么 Flink 既可以流处理又可以批处理呢?
如果要进行流计算,Flink 会初始化一个流执行环境 StreamExecutionEnvironment,然后利用这个执行环境构建数据流 DataStream。
StreamExecutionEnvironment see = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<WikipediaEditEvent> edits = see.addSource(new WikipediaEditsSource());
如果要进行批处理计算,Flink 会初始化一个批处理执行环境 ExecutionEnvironment,然后利用这个环境构建数据集 DataSet。
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet text = env.readTextFile("/path/to/file");
然后在 DataStream 或者 DataSet 上执行各种数据转换操作(transformation),这点很像 Spark。不管是流处理还是批处理,Flink 运行时的执行引擎是相同的,只是数据源不同而已。
实现
浓浓的tf 提交dag的味道,区别是flink 和spark 一样是集群先跑起来,再提交任务。中间设计到graph 拆分为task 、调度task 到具体TaskManager的过程。
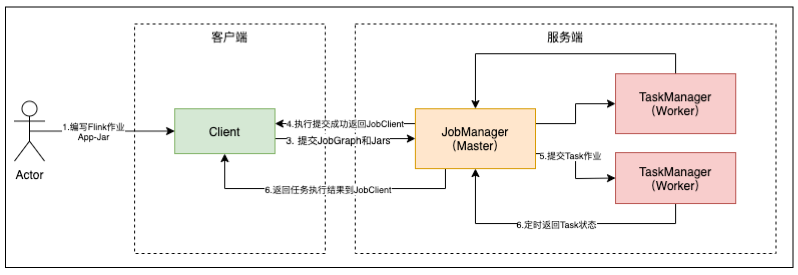
- JobManager 管理节点,每个集群至少一个,管理整个集群计算资源,Job管理与调度执行,以及 Checkpoint 协调。
- TaskManager :每个集群有多个TM ,负责计算资源提供。
- Client :本地执行应用 main() 方法解析JobGraph 对象,并最终将JobGraph 提交到 JobManager 运行,同时监控Job执行的状态。
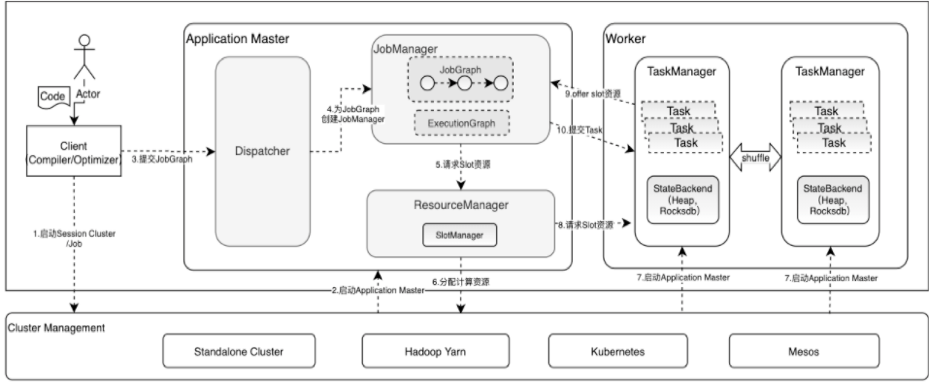
dispatcher 任务调度
- 一个jobGraph 对应一个 jobManager(JobMaster) 双层资源调度
- cluster -> job, slotManager 会给 jobGraph 对应的jobManager 分配多个slot (slotPool)
- job -> task, 单个slot 可以用于一个或多个task 执行; 但相同的task 不能在一个slot 中运行
Flink 四种 Graph 转换
- 第一层: Program -> StreamGraph。算子之间的拓扑关系。
- 第二层: StreamGraph -> JobGraph。 不涉及数据跨节点交换 的Operation 会组成 OperatorChain(最终在一个task 里运行)
- 第三层: JobGraph -> ExecutionGraph
- 第四层: Execution -> 物理执行计划
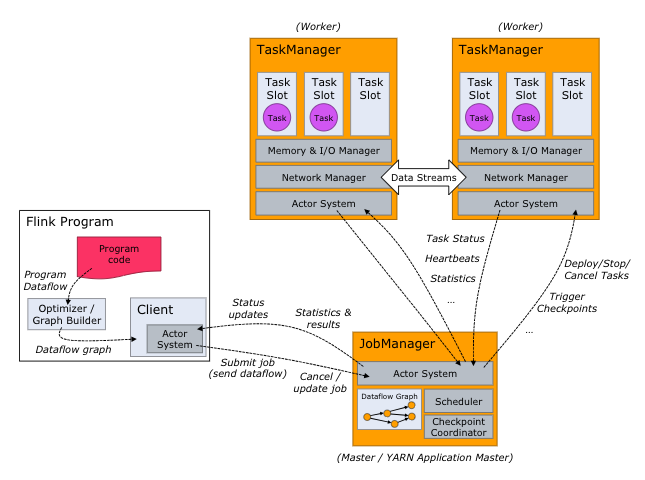
其它
流式处理,支持一条一条处理, 对于扩展operation,spark/flink client 会把main代码 和 jar 打包成一个package 上传到Master,jobGraph上附带job 相关的自定义jar信息, taskManager 执行task 前下载 相应的jar (然后由classloader)加载执行,而tf 因为其特殊性 就只能自定义op了。