前言
李智慧:软件编程技术出现已经半个多世纪了,核心价值就是把现实世界的业务操作搬到计算机上,通过计算机软件和网络进行业务和数据处理。但是时至今日,能用计算机软件提高效率的地方,几乎已经被全部发掘过了,在这种情况下,如果想让软件再成百上千倍地提高我们的生活和工作效率,使用以前的那套“分析用户需求和业务场景,进行软件设计和开发”的做法显然是不可能的了。 那如何走出这个困局呢?我觉得,要想让计算机软件包括互联网应用,能够继续提高我们的生活工作效率,那就必须能够发掘出用户自己都没有发现的需求,必须洞悉用户自己都不了解的自己。计算机软件不能再像以前那样,等用户输入操作,然后根据编写好的逻辑执行用户的操作,而是应该能够预测用户的期望,在你还没想好要做什么的情况下,主动提供操作建议和选项,提醒你应该做什么。所以,我同意这样一种说法:在未来,软件开发将是“面向 AI 编程”,软件的核心业务逻辑和价值将围绕机器学习的结果也就是 AI 展开,软件工程师的工作就是考虑如何将机器学习的结果更好地呈现出来,如何更好地实现人和 AI 的交互。
事实上,公司到了一定规模,产品功能越来越复杂,人员越来越多,不管用什么驱动,最后一定都是数据驱动。没有量化的数据,不足以凝聚团队的目标,甚至无法降低团队间的内耗。这个时候哪个部门能有效利用数据,能用数据说话,能用数据打动老板,哪个部门就能成为公司的驱动核心,在公司拥有更多话语权。我们学大数据,手里用的是技术,眼里要看到数据,要让数据为你所用。数据才是核心才是不可代替的,技术并不是。
大数据处理的主要应用场景包括数据分析、数据挖掘与机器学习。数据分析主要使用 Hive、Spark SQL 等 SQL 引擎完成;数据挖掘与机器学习则有专门的机器学习框架 TensorFlow、Mahout 以及 MLlib 等,内置了主要的机器学习和数据挖掘算法。此外,大数据要存入分布式文件系统(HDFS),要有序调度 MapReduce 和 Spark 作业执行,并能把执行结果写入到各个应用系统的数据库中,还需要有一个大数据平台整合所有这些大数据组件和企业应用系统。
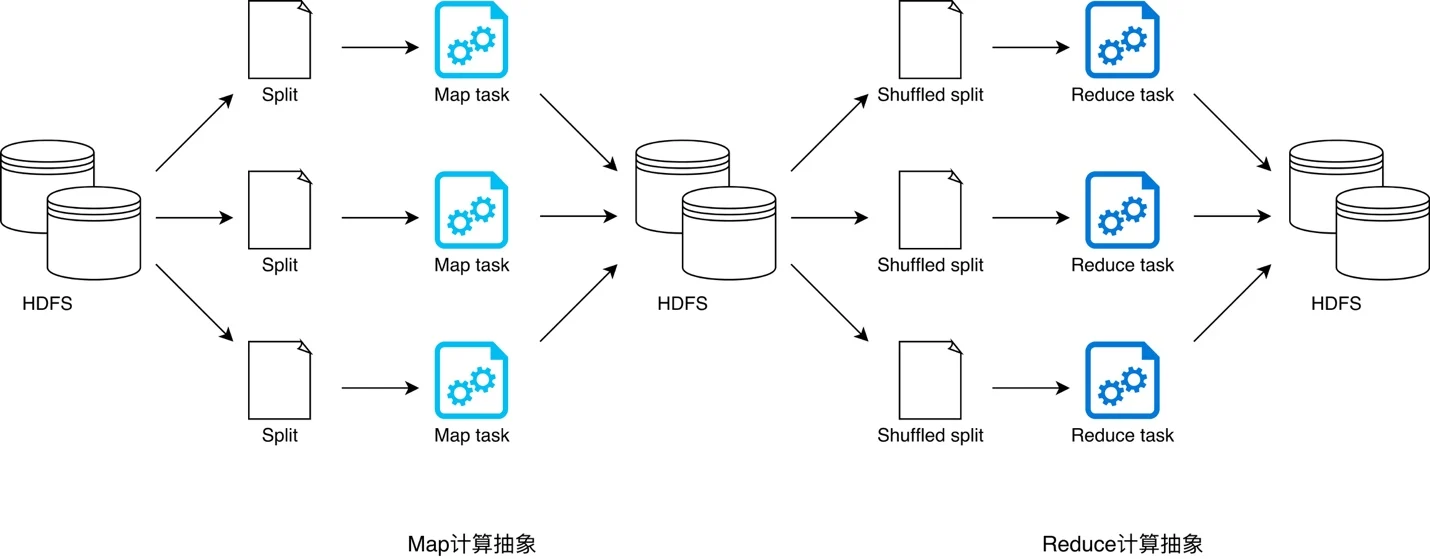
移动计算程序到数据所在位置进行计算是如何实现的呢?
- 将待处理的大规模数据存储在服务器集群的所有服务器上,主要使用 HDFS 分布式文件存储系统,将文件分成很多块(Block),以块为单位存储在集群的服务器上。
- 大数据引擎根据集群里不同服务器的计算能力,在每台服务器上启动若干分布式任务执行进程,这些进程会等待给它们分配执行任务。
- 使用大数据计算框架支持的编程模型进行编程,比如 Hadoop 的 MapReduce 编程模型,或者 Spark 的 RDD 编程模型。应用程序编写好以后,将其打包,MapReduce 和 Spark 都是在 JVM 环境中运行,所以打包出来的是一个 Java 的 JAR 包。
- 用 Hadoop 或者 Spark 的启动命令执行这个应用程序的 JAR 包,首先执行引擎会解析程序要处理的数据输入路径,根据输入数据量的大小,将数据分成若干片(Split),每一个数据片都分配给一个任务执行进程去处理。
- 任务执行进程收到分配的任务后,检查自己是否有任务对应的程序包,如果没有就去下载程序包,下载以后通过反射的方式加载程序。走到这里,最重要的一步,也就是移动计算就完成了。PS:传递是jar包,但是 worker 进程加载的应该是 Map 或Reduce类 人不是执行jar本身的main函数,jar包本身的main函数是提交任务用的
- 加载程序后,任务执行进程根据分配的数据片的文件地址和数据在文件内的偏移量读取数据,并把数据输入给应用程序相应的方法去执行,从而实现在分布式服务器集群中移动计算程序,对大规模数据进行并行处理的计算目标。
大数据计算的核心思路是移动计算比移动数据更划算。既然计算方法跟传统计算方法不一样,移动计算而不是移动数据,那么用传统的编程模型进行大数据计算就会遇到很多困难,因此 Hadoop 大数据计算使用了一种叫作 MapReduce 的编程模型。
- 为什么说 MapReduce 是一种非常简单又非常强大的编程模型?简单在于其编程模型只包含 Map 和 Reduce 两个过程,map 的主要输入是一对
<Key,Value>值,经过 map 计算后输出 一对<Key,Value>值;然后将相同 Key 合并,形成<Key,Value集合>;再将这个<Key,Value集合>输入 reduce,经过计算输出零个或多个<Key,Value>对。 - MapReduce 又是非常强大的,不管是关系代数运算(SQL 计算),还是矩阵运算(图计算),大数据领域几乎所有的计算需求都可以通过 MapReduce 编程来实现。
一个 MapReduce 程序要想在分布式环境中执行,并处理海量的大规模数据,还需要一个计算框架,能够调度执行这个 MapReduce 程序,使它在分布式的集群中并行运行,而这个计算框架也叫 MapReduce。
- 如何为每个数据块分配一个 Map 计算任务,也就是代码是如何发送到数据块所在服务器的,发送后是如何启动的,启动以后如何知道自己需要计算的数据在文件什么位置(BlockID 是什么)。
- 处于不同服务器的 map 输出的 ,如何把相同的 Key 聚合在一起发送给 Reduce 任务进行处理。PS: 分布式计算需要将不同服务器上的相关数据合并到一起进行下一步计算,这就是 shuffle。不管是 MapReduce 还是 Spark,只要是大数据批处理计算,一定都会有 shuffle 过程,只有让数据关联起来,数据的内在关系和价值才会呈现出来。移动计算主要是map阶段,reduce阶段数据还是要移动数据合并关联,不然很多计算无法完成。
不管是批处理计算还是流处理计算,都需要庞大的计算资源,需要将计算任务分布到一个大规模的服务器集群上。那么如何管理这些服务器集群的计算资源,如何对一个计算请求进行资源分配,这就是大数据集群资源管理框架 Yarn 的主要作用。各种大数据计算引擎,不管是批处理还是流处理,都可以通过 Yarn 进行资源分配,运行在一个集群中。
其它
很多大数据产品都是这样的架构方案:Storm,一个 Nimbus,多个 Supervisor;Spark,一个 Master,多个 Slave。大数据因为要对数据和计算任务进行统一管理,所以和互联网在线应用不同,需要一个全局管理者。而在线应用因为每个用户请求都是独立的,而且为了高性能和便于集群伸缩,会尽量避免有全局管理者。
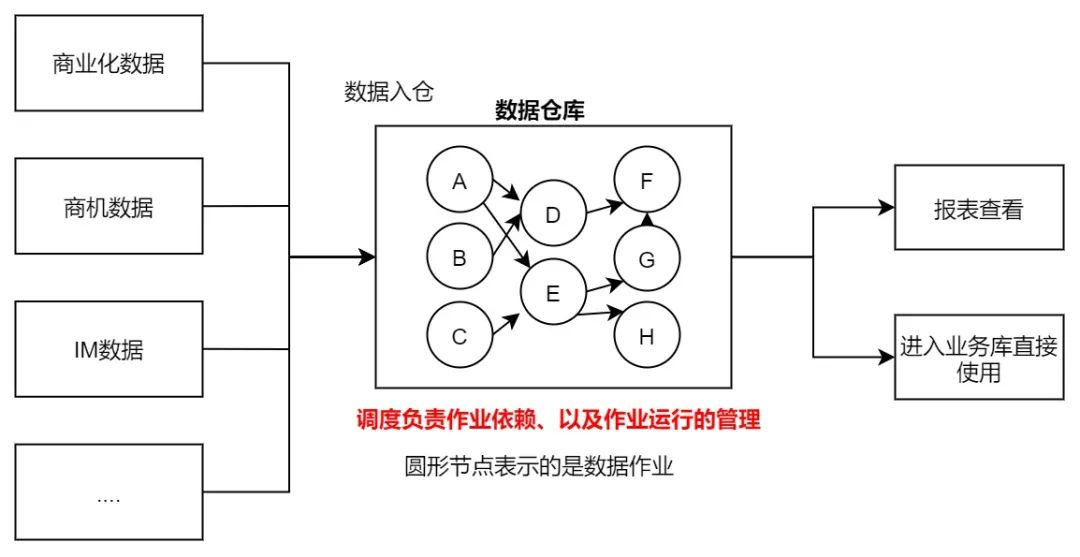
贝壳大数据任务调度DAG体系设计实践 数仓不是建几个表就好了。