简介
- 简介
- cpu 指令执行
- 代码执行
- 多层次内存结构
- cpu/服务器 三大体系numa smp mpp
- 为什么会有人觉得优化没有必要,因为他们不理解有多耗时
- 并行计算能力
- SIMD(Single Instruction Multiple Data)
- 其它
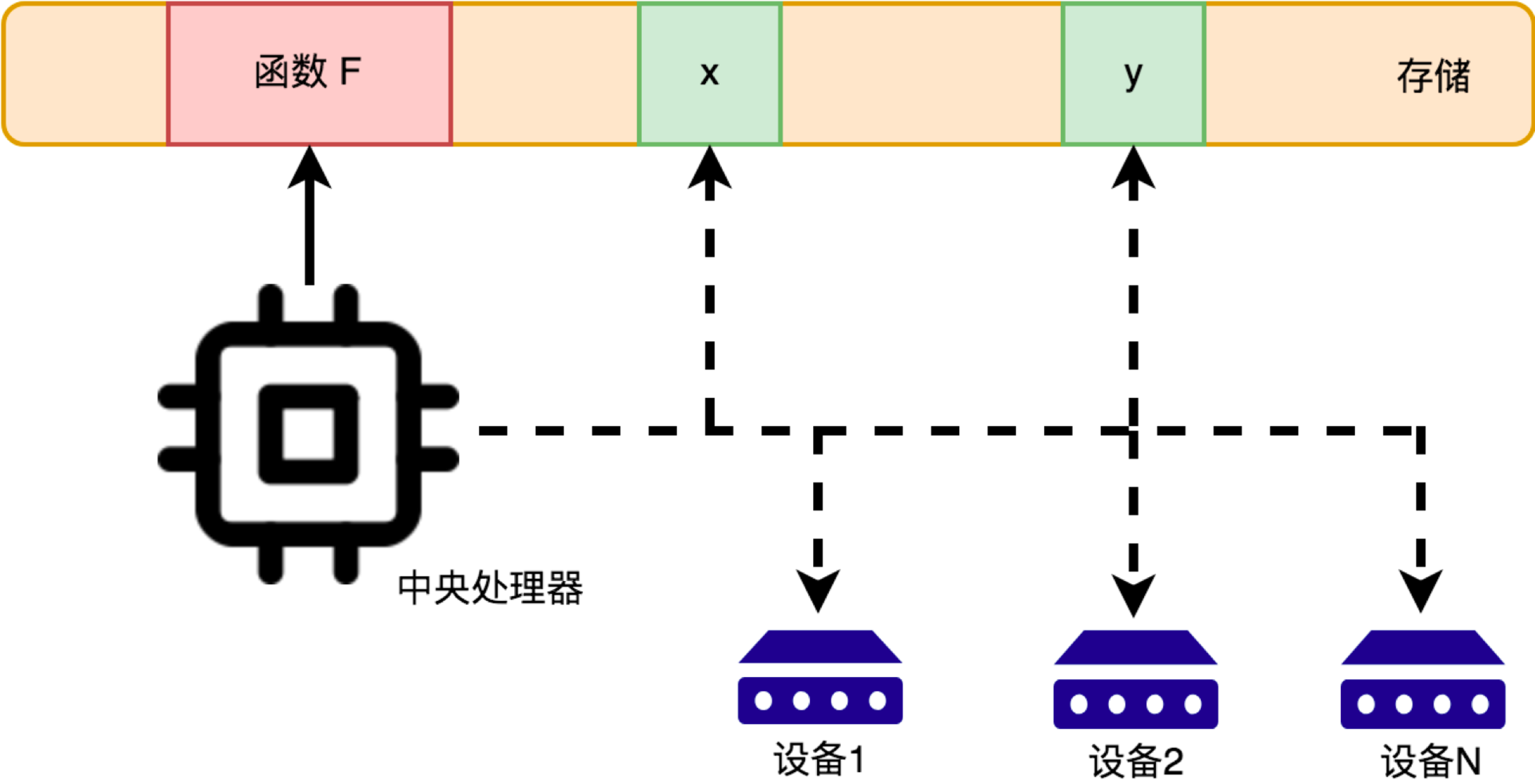
- CPU 可以直接访问的存储资源非常少,只有:寄存器、内存(RAM)、主板上的 ROM。
- 寄存器的访问速度非常非常快,但是数量很少,大部分程序员不直接打交道,而是由编程语言的编译器根据需要自动选择寄存器来优化程序的运行性能。
- 内存的地位非常特殊,它是唯一的 CPU 内置支持,且和程序员直接会打交道的基础资源。
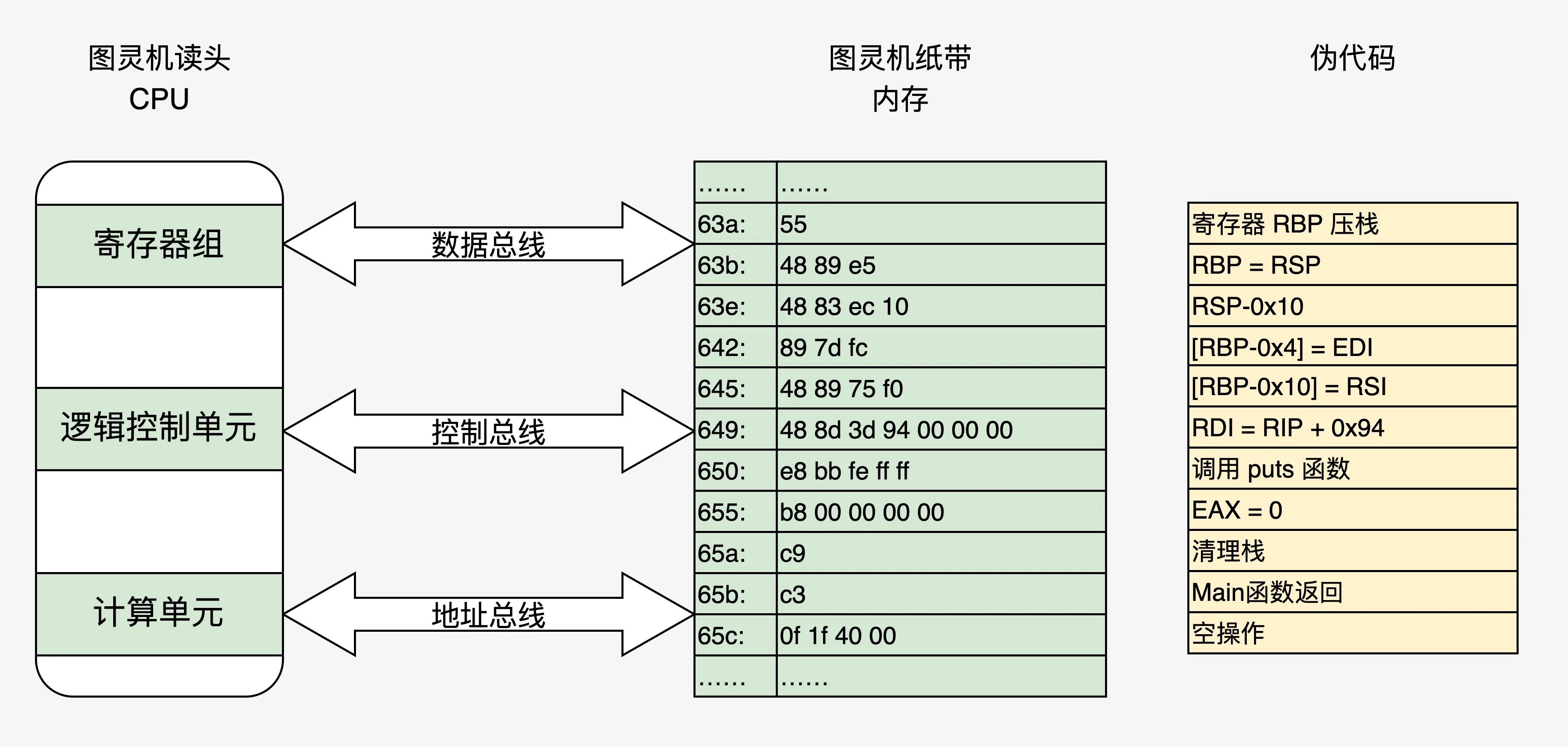
cpu 指令执行
计算机是如何读懂0和1的?- CPU (上)计算机是如何读懂0和1的?- CPU (下) 可以学到几个问题
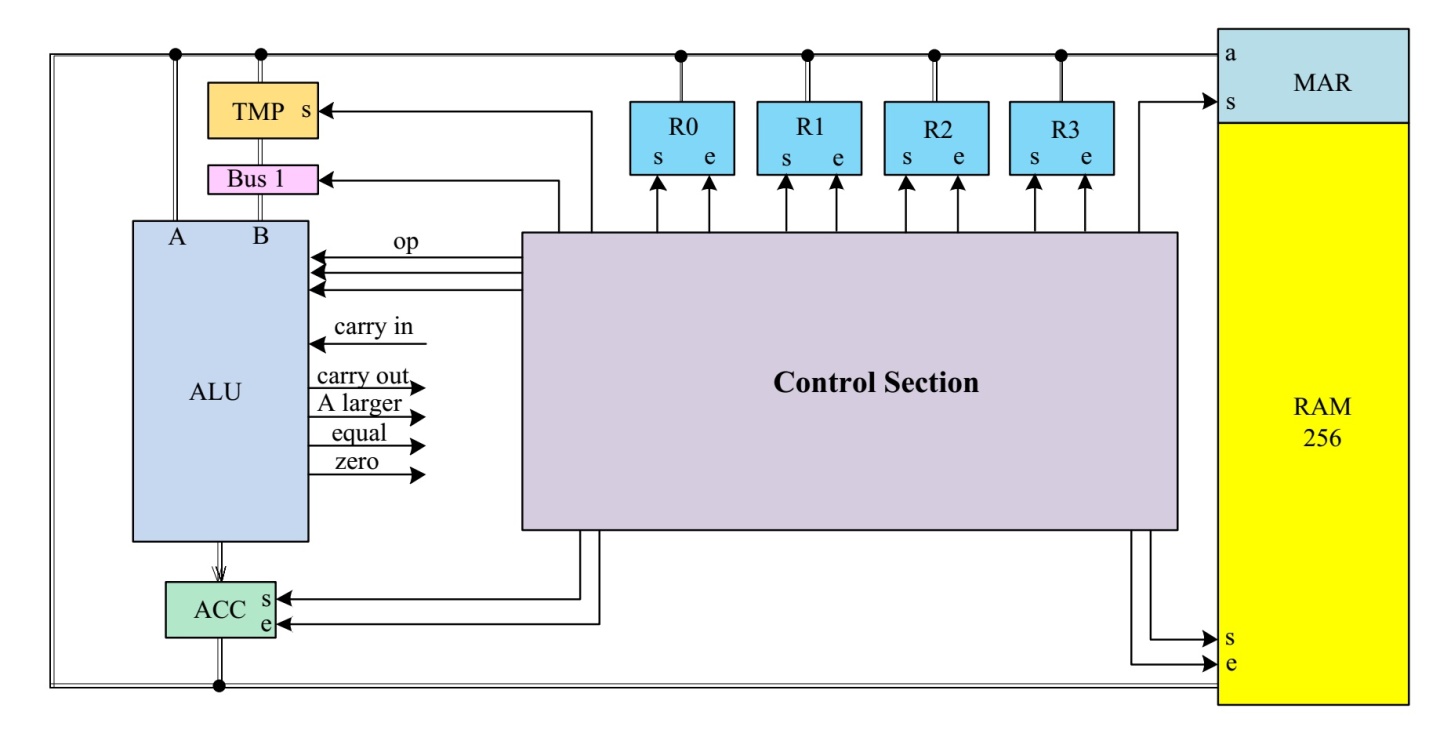
- alu 是如何构成的
- 时钟如何驱动寄存器、控制单元、计算单元alu
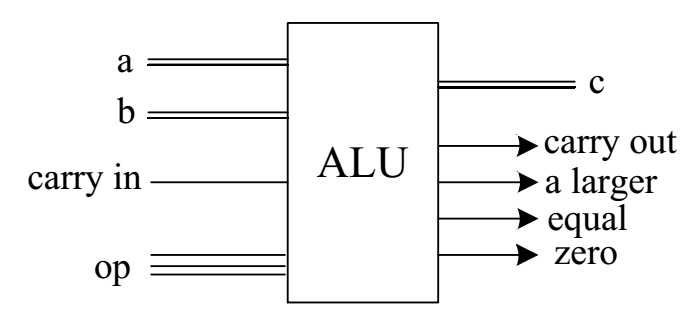
ALU 包含加法器、移位器(左)、移位器(右)、比较器、与门、非门、或门 等逻辑电路,所有的单元都有输入a,对于需要两个输入的单元,b也被连接。通过op操作码,可以选择不同的逻辑或算数单元。ALU计算会输出四个标志位,分别为:carry out(进位)、a larger、equal和zero。
ALU op操作码所对应的选择为:
| op | 逻辑/算数单元 | 含义 |
|---|---|---|
| 000 | ADD | 加法 |
| 001 | SHR | 右移 |
| 010 | SHL | 左移 |
| 011 | NOT | 取反 |
| 100 | AND | 与 |
| 101 | OR | 或 |
| 110 | XOR | 异或 |
| 111 | CMP | 比较 |
对于一个8位CPU来说,指令可以分为两大类,一类为ALU相关指令,主要包括需要ALU参与完成的相关指令,比如加法、移位、比较等;另一类是非ALU相关指令,比如加载数据,存储数据,跳转等。无论哪种指令,都可以分为前4位和后4位,前四位和动作有关,后四位和数据有关。
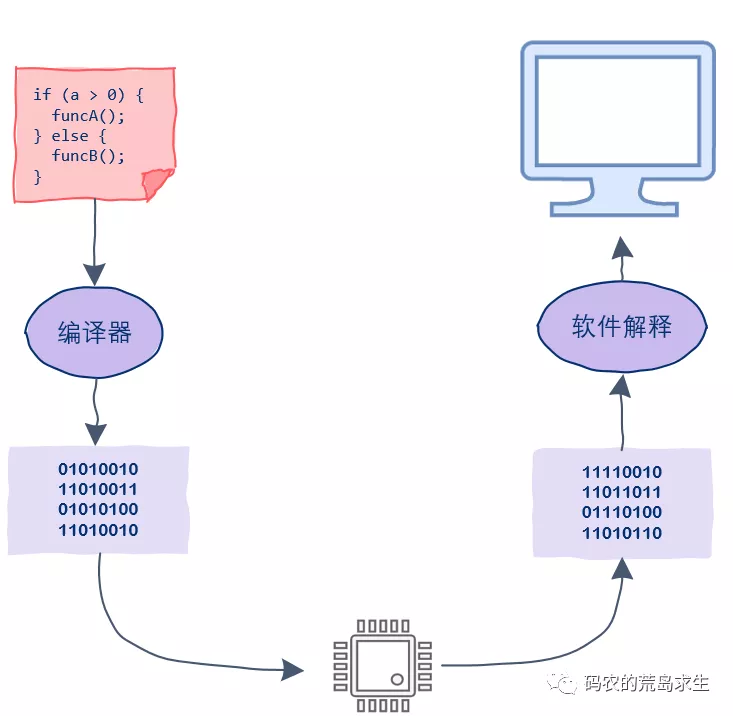
代码执行
一行代码能够执行,必须要有可以执行的上下文环境,包括:指令寄存器、数据寄存器、栈空间等内存资源。
许式伟:中央处理器支持的指令大体如下:
- 计算类,也就是支持我们大家都熟知的各类数学运算,如加减乘除、sin/cos 等等;
- I/O 类,从存储读写数据,从输入输出设备读数据、写数据;
- 指令跳转类,在满足特定条件下跳转到新的当前程序执行位置、调用自定义的函数。
为什么可以流水线/乱序执行?我们通常会把 CPU 看做一个整体,把 CPU 执行指令的过程想象成,依此检票进站的过程,改变不同乘客的次序,并不会加快检票的速度。所以,我们会自然而然地认为改变顺序并不会改变总时间。但当我们进入 CPU 内部,会看到 CPU 是由多个功能部件构成的。一条指令执行时要依次用到多个功能部件,分成多个阶段,虽然每条指令是顺序执行的,但每个部件的工作完成以后,就可以服务于下一条指令,从而达到并行执行的效果。比如典型的 RISC 指令在执行过程会分成前后共 5 个阶段。
- IF:获取指令;
- ID(或 RF):指令解码和获取寄存器的值;
- EX:执行指令;
- ME(或 MEM):内存访问(如果指令不涉及内存访问,这个阶段可以省略);
- WB:写回寄存器。
在执行指令的阶段,不同的指令也会由不同的单元负责。所以在同一时刻,不同的功能单元其实可以服务于不同的指令。
从JVM并发看CPU内存指令重排序(Memory Reordering)我们知道现代CPU的主频越来越高,与cache的交互次数也越来越多。当CPU的计算速度远远超过访问cache时,会产生cache wait,过多的cache wait就会造成性能瓶颈。针对这种情况,多数架构(包括X86)采用了一种将cache分片的解决方案,即将一块cache划分成互不关联地多个 slots (逻辑存储单元,又名 Memory Bank 或 Cache Bank),CPU可以自行选择在多个 idle bank 中进行存取。这种 SMP(指在一个计算机上汇集了一组处理器,各CPU之间共享内存子系统以及总线结构) 的设计,显著提高了CPU的并行处理能力,也回避了cache访问瓶颈。
Memory Bank的划分:一般 Memory bank 是按cache address来划分的。比如 偶数adress 0×12345000分到 bank 0, 奇数address 0×12345100分到 bank1。
重排序的种类
- 编译期重排。编译源代码时,编译器依据对上下文的分析,对指令进行重排序,使其更适合于CPU的并行执行。
- 运行期重排,CPU在执行过程中,动态分析依赖部件的效能(CPU0检查 bank0 的可用性,发现 bank0 处于 busy 状态,那么本来写入cache bank0的数据操作会延后),对指令做重排序优化。
前者是编译器进行的,不同语言不同。后者是cpu 层面的,所有使用共享内存模型进行线程通信的语言都要面对的。
许式伟:最早期的计算机毫无疑问是单任务的,计算的职能也多于存储的职能。每次做完任务,计算机的状态重新归零(回到初始状态)都没有关系。汇编语言的出现要早于操作系统。操作系统的核心目标是软件治理,只有在计算机需要管理很多的任务时,才需要有操作系统。
多层次内存结构
RAM 分为动态和静态两种,静态 RAM 由于集成度较低,一般容量小,速度快,而动态 RAM 集成度较高,主要通过给电容充电和放电实现,速度没有静态 RAM 快,所以一般将动态 RAM 做为主存,而静态 RAM 作为 CPU 和主存之间的高速缓存 (cache),用来屏蔽 CPU 和主存速度上的差异,也就是我们经常看到的 L1 , L2 缓存。
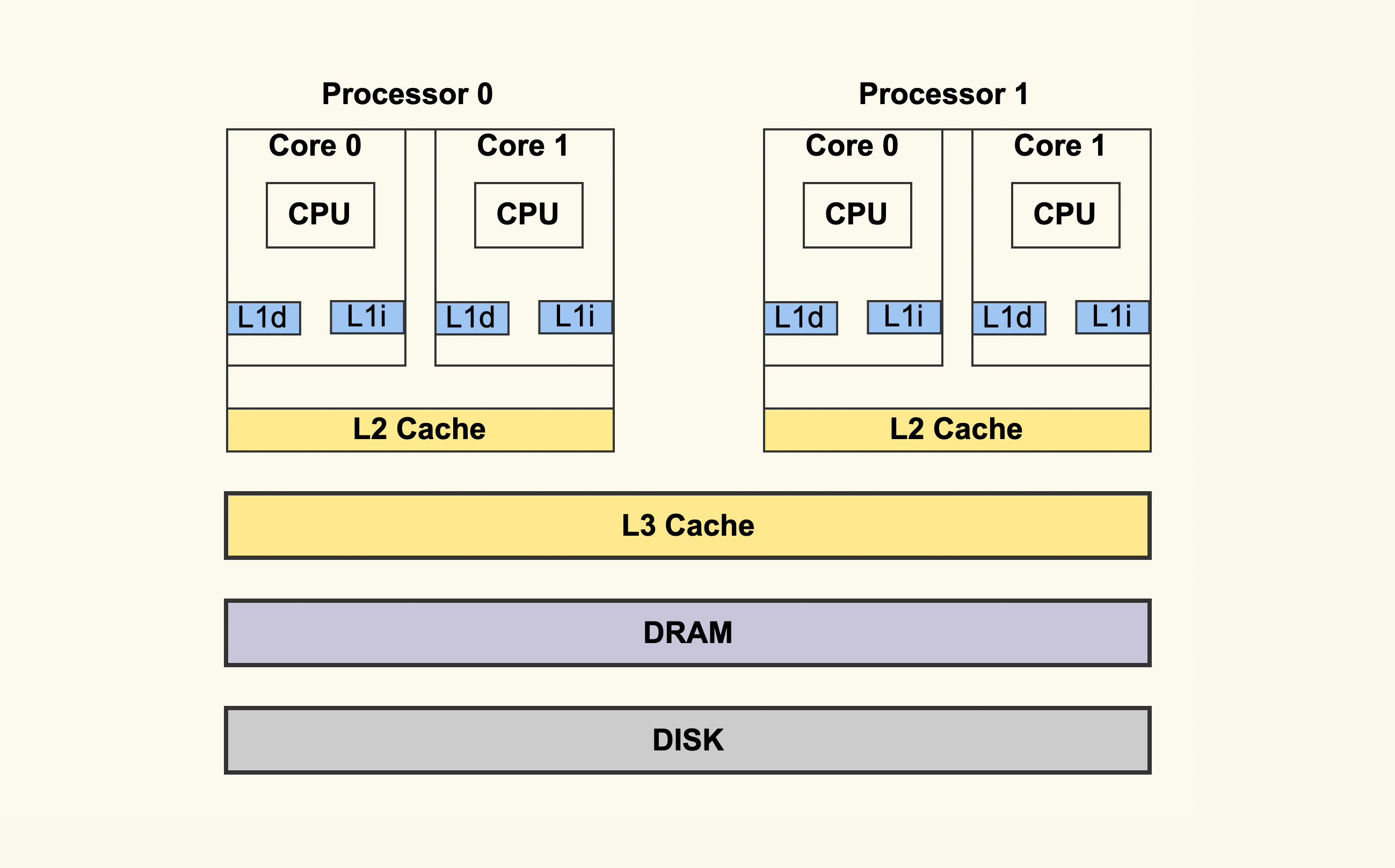
一个 CPU 处理器中一般有多个运行核心,我们把一个运行核心称为一个物理核,每个物理核都可以运行应用程序。每个物理核都拥有私有的一级缓存(Level 1 cache,简称 L1 cache),包括一级指令缓存和一级数据缓存,以及私有的二级缓存(Level 2 cache,简称 L2 cache)。L1 和 L2 缓存是每个物理核私有的,不同的物理核还会共享一个共同的三级缓存。另外,现在主流的 CPU 处理器中,每个物理核通常都会运行两个超线程,也叫作逻辑核。同一个物理核的逻辑核会共享使用 L1、L2 缓存。PS:笔者经历过cpu密集型服务(nlp 相关的机器训练,占用一个逻辑核)与其它业务(占用一个逻辑核)在一个 物理核上 导致性能下降明显的事情,因为k8s 也支持 分配完整物理核的策略(否则就不调度)
缓存速度的差异
| 从CPU到 | 大约需要的 CPU 周期 | 大约需要的时间 |
|---|---|---|
| 主存 | 约60-80纳秒 | |
| QPI 总线传输(between sockets, not drawn) | 约20ns | |
| L3 cache | 约40-45 cycles, | 约15ns |
| L2 cache | 约10 cycles, | 约3ns |
| L1 cache | 约3-4 cycles, | 约1ns |
| 寄存器 | 1 cycle |
当CPU执行运算的时候,它先去L1查找所需的数据,再去L2,然后是L3,最后如果这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。如果你的目标是让端到端的延迟只有 10毫秒,而其中花80纳秒去主存拿一些未命中数据的过程将占很重的一块。如果你在做一些很频繁的事,你要确保数据在L1缓存中。
当然,缓存命中率是很笼统的,具体优化时还得一分为二。比如,你在查看 CPU 缓存时会发现有 2 个一级缓存,这是因为,CPU 会区别对待指令与数据。虽然在冯诺依曼计算机体系结构中,代码指令与数据是放在一起的,但执行时却是分开进入指令缓存与数据缓存的,因此我们要分开来看二者的缓存命中率。
- 提高数据缓存命中率,考虑cache line size
- 提高指令缓存命中率,CPU含有分支预测器,如果分支预测器可以预测接下来要在哪段代码执行(比如 if 还是 else 中的指令),就可以提前把这些指令放在缓存中,CPU 执行时就会很快。例如,如果代码中包含if else,不要让每次执行if else 太过于随机。
在一个 CPU 核上运行时,应用程序需要记录自身使用的软硬件资源信息(例如栈指针、CPU 核的寄存器值等),我们把这些信息称为运行时信息。同时,应用程序访问最频繁的指令和数据还会被缓存到 L1、L2 缓存上,以便提升执行速度。但是,在多核 CPU 的场景下,一旦应用程序需要在一个新的 CPU 核上运行,那么,运行时信息就需要重新加载到新的 CPU 核上。而且,新的 CPU 核的 L1、L2 缓存也需要重新加载数据和指令,这会导致程序的运行时间增加。因此,操作系统(调度器)提供了将进程或者线程绑定到某一颗 CPU 上运行的能力(PS:就好像将pod 调度到上次运行它的node)。建议绑定物理核,以防止绑到一个逻辑核时,因为任务较多导致目标线程迟迟无法被调度的情况。
缓存的存取——cache line
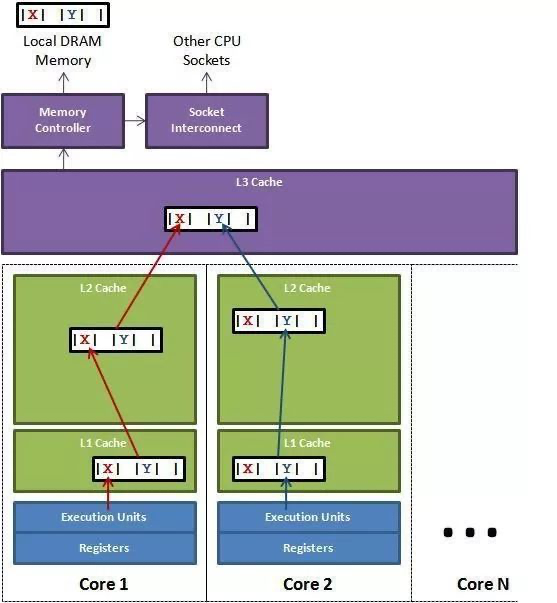
Cache 的存取与替换都是以缓存行(Cacheline)为单位。。cpu和内存的速度差异 ==> 缓存 ==> 多级缓存 ==> Cache是由很多个cache line组成的。每个cache line通常是64字节,并且它有效地引用主内存中的一块儿地址。CPU每次从主存中拉取数据时,会把相邻的数据也存入同一个cache line。每次改写 Cache 中的数据都会将整个 Cache Line 置为无效。
- 下次访问第二个变量时,便需要从内存中加载到缓存,再加载到cpu。
- 伪共享问题。CPU 0 和 同时 CPU 1 同时写一个内存地址,就会产生竞争。在总线仲裁后,先写的数据就会被后写的数据给覆盖掉。在这种场景下,就需要同步原语了,比如使用 atomic 操作。假设定义了一个结构体,该结构体里的两个成员 a 和 b 在地址上是连续的。如果 CPU 0 去写 a,同时 CPU 1 去读 b 的话,此时不会有竞争,因为 a 和 b 是不同的地址。不过,a 和 b 由于在地址上是连续的,它们可能会位于同一个 Cache Line 中。另外一个 CPU 中的线程在读写数据时就会发生 cache miss,然后去内存读数据,这就大大降低了性能。
java 和c 都有相关机制来解决伪共享问题。
struct foo {
int a;
int b ____cacheline_aligned;
};
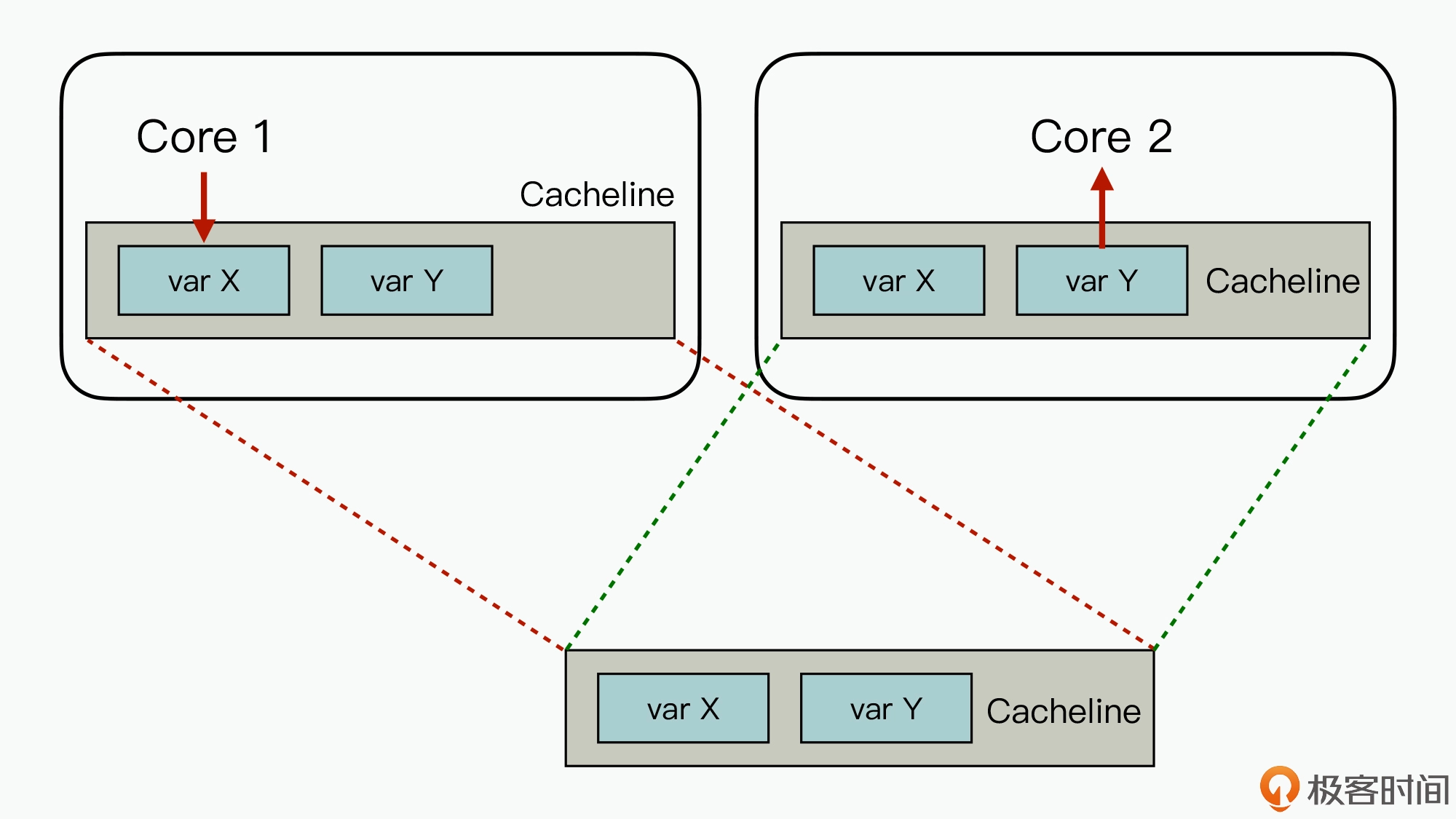
通过内存对齐可以避免一个字段同时存在两个缓存行里的情况,但还是无法完全规避缓存伪共享的问题,也就是一个缓存行中存了多个变量,而这几个变量在多核 CPU 并行的时候,会导致竞争缓存行的写权限,当其中一个 CPU 写入数据后,这个字段对应的缓存行将失效,导致这个缓存行的其他字段也失效。
在 Disruptor 中,通过填充几个无意义的字段,让对象的大小刚好在 64 字节,一个缓存行的大小为64字节,这样这个缓存行就只会给这一个变量使用,从而避免缓存行伪共享,但是在 jdk7 中,由于无效字段被清除导致该方法失效,只能通过继承父类字段来避免填充字段被优化,而 jdk8 提供了注解@Contended 来标示这个变量或对象将独享一个缓存行,使用这个注解必须在 JVM 启动的时候加上 -XX:-RestrictContended 参数,其实也是用空间换取时间。
如何让多核CPU的高速缓存保持一致?
要解决缓存一致性问题,首先要解决的是多个 CPU 核心之间的数据传播问题。最常见的一种解决方案叫作总线嗅探(Bus Snooping)。本质上就是把所有的读写请求都通过总线(Bus)广播给所有的 CPU 核心,然后让各个核心去“嗅探”这些请求,再根据本地的情况进行响应。
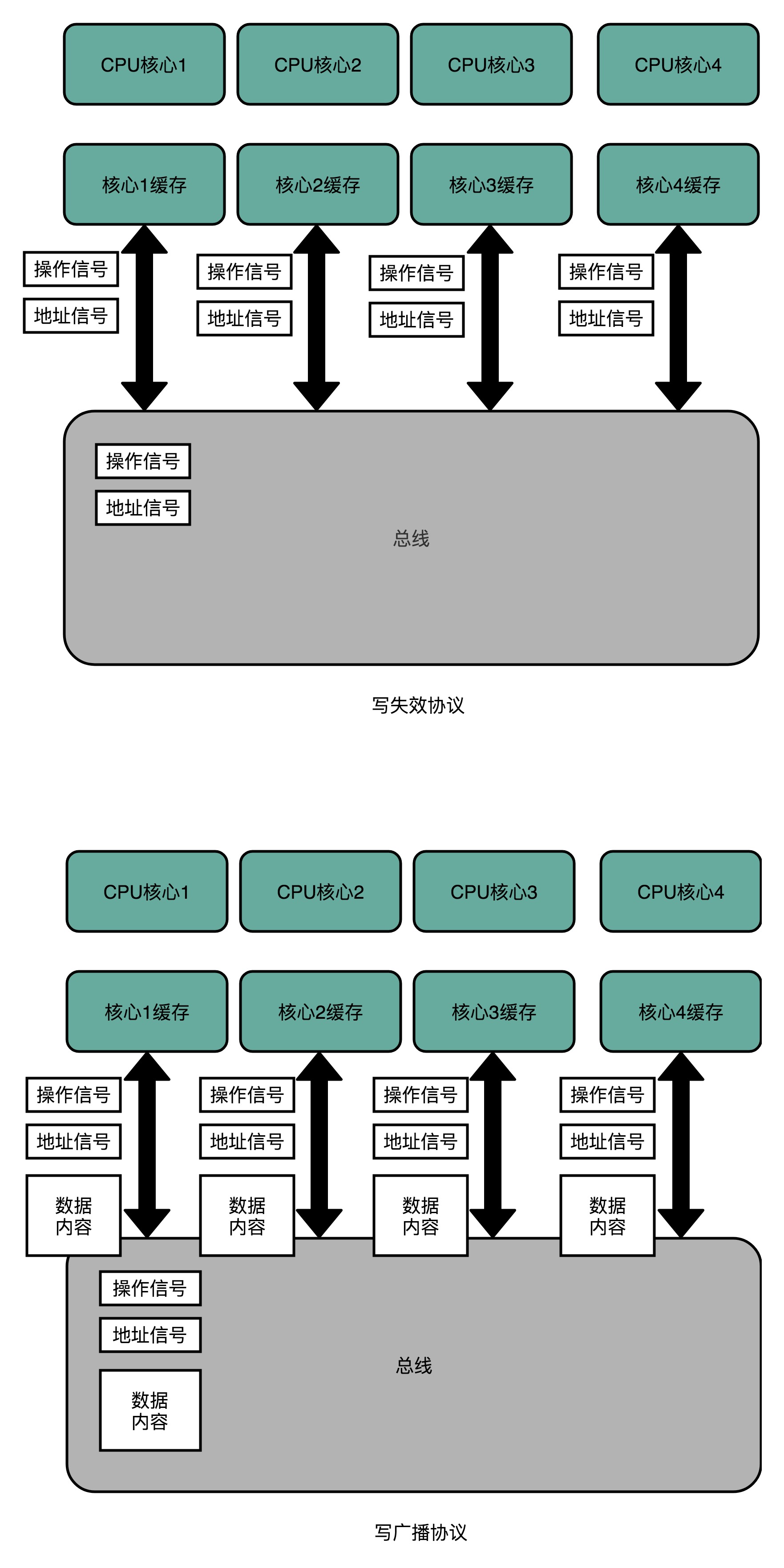
MESI 协议,是一种叫作写失效(Write Invalidate)的协议。在这个 CPU 核心写入 Cache 之后,它会去广播一个“失效”请求告诉所有其他的 CPU 核心。其他的 CPU 核心,只是去判断自己是否也有一个“失效”版本的 Cache Block,然后把这个也标记成失效的就好了。MESI 协议来自于我们对 Cache Line 的四个不同的标记,分别是:
- M:代表已修改(Modified)。Cache Block 里面的内容已经更新过,但是还没有写回到主内存里面。
- E:代表独占(Exclusive).对应的 Cache Line 只加载到了当前 CPU 核所拥有的 Cache 里。其他的 CPU 核,并没有加载对应的数据到自己的 Cache 里。
- S:代表共享(Shared)。同样的数据在多个 CPU 核心的 Cache 里都有。当我们想要更新 Cache 里面的数据的时候,不能直接修改,而是要先向所有的其他 CPU 核心广播一个请求,要求先把其他 CPU 核心里面的 Cache,都变成无效的状态,然后再更新当前 Cache 里面的数据。
- I:代表已失效(Invalidated).这个 Cache Block 里面的数据已经失效了(被别的cpu core修改过)
整个 MESI 的状态变更,则是根据来自自己 CPU 核心的请求,以及来自其他 CPU 核心通过总线传输过来的操作信号和地址信息,进行状态流转的一个有限状态机。Cache 硬件会监控所有 CPU 上 Cache 的操作,根据相应的操作使得 Cache 里的数据行在上面这些状态之间切换。Intel CPU使用了MESI协议。
从CPU Cache出发彻底弄懂volatile/synchronized/cas机制各CPU都会通过总线嗅探来监视其他CPU,一旦某个CPU对自己Cache中缓存的共享变量做了修改(能做修改的前提是共享变量所在的缓存行的状态不是无效的),那么就会导致其他缓存了该共享变量的CPU将该变量所在的Cache Line置为无效状态,在下次CPU访问无效状态的缓存行时会首先要求对共享变量做了修改的CPU将修改从Cache写回主存,然后自己再从主存中将最新的共享变量读到自己的缓存行中。
缓存一致性协议通过缓存锁定来保证CPU修改缓存行中的共享变量并通知其他CPU将对应缓存行置为无效这一操作的原子性,即当某个CPU修改位于自己缓存中的共享变量时会禁止其他也缓存了该共享变量的CPU访问自己缓存中的对应缓存行,并在缓存锁定结束前通知这些CPU将对应缓存行置为无效状态。在缓存锁定出现之前,是通过总线锁定来实现CPU之间的同步的,即CPU在回写主存时会锁定总线不让其他CPU访问主存,但是这种机制开销较大。
有序执行内存操作——内存屏障
Compiler 和 cpu 经常搞一些 optimizations,这种单线程视角下的优化在多线程环境下是不合时宜的,为此要用 memory barriers 来禁止 Compiler 和 cpu 搞这些小动作。 For purposes here, I assume that the compiler and the hardware don’t introduce funky optimizations (such as eliminating some “redundant” variable reads, a valid optimization under a single-thread assumption).
x86指令集中的内存屏障指令是:
lfence (asm), void _mm_lfence (void) 读操作屏障
sfence (asm), void _mm_sfence (void)[1] 写操作屏障
mfence (asm), void _mm_mfence (void)[2] 读写操作屏障
常见的x86/x64,通常使用lock指令前缀加上一个空操作来实现,注意当然不能真的是nop指令,但是可以用来实现空操作的指令其实是很多的,比如Linux中采用的addl $0, 0 (%esp)。
可以认为lock 指令本身有锁总线的功能,然后因为锁总线的功能导致前后指令无法乱序,进而编译器和cpu 碰到lock 也不会乱序执行,进而用lock 锁总线之外附赠一个禁止乱序执行的效果(内存屏障)。java 或go 的 atomic 包会被编译带lock 的指令码。
Java和操作系统交互细节插入内存屏障的指令,会根据指令类型不同有不同的效果,例如在 monitorexit 释放锁后会强制刷新缓存,而 volatile 对应的内存屏障会在每次写入后强制刷新到主存,并且由于 volatile 字段的特性,编译器无法将其分配到寄存器,所以每次都是从主存读取,所以 volatile 适用于读多写少得场景
cpu/服务器 三大体系numa smp mpp
- SMP(Symmetric Multi-Processor) 所谓对称多处理器结构,是指服务器中多个CPU对称工作,无主次或从属关系。各CPU共享相同的物理内存,每个 CPU访问内存中的任何地址所需时间是相同的,因此SMP也被称为一致存储器访问结构(UMA:Uniform Memory Access)。SMP服务器的主要特征是共享,系统中所有资源(CPU、内存、I/O等)都是共享的。也正是由于这种特征,导致了SMP服务器的主要问题,那就是它的扩展能力非常有限。对于SMP服务器而言,每一个共享的环节都可能造成SMP服务器扩展时的瓶颈,而最受限制的则是内存。由于每个CPU必须通过相同的内存总线访问相同的内存资源,因此随着CPU数量的增加,内存访问冲突将迅速增加,最终会造成CPU资源的浪费,使 CPU性能的有效性大大降低。实验证明,SMP服务器CPU利用率最好的情况是2至4个CPU。
- NUMA(Non-Uniform Memory Access)基本特征是具有多个CPU模块,每个CPU模块由多个CPU(如4个)组成,并且具有独立的本地内存、I/O槽口等。由于其节点之间可以通过互联模块(如称为Crossbar Switch)进行连接和信息交互,因此每个CPU可以访问整个系统的内存(这是NUMA系统与MPP系统的重要差别)。显然,访问本地内存的速度将远远高于访问远地内存(系统内其它节点的内存)的速度,这也是非一致存储访问NUMA的由来。由于这个特点,为了更好地发挥系统性能,开发应用程序时需要尽量减少不同CPU模块之间的信息交互。
- MPP(Massive Parallel Processing)其基本特征是由多个SMP服务器(每个SMP服务器称节点)通过节点互联网络连接而成,每个节点只访问自己的本地资源(内存、存储等),是一种完全无共享(Share Nothing)结构,因而扩展能力最好,理论上其扩展无限制。在MPP系统中,每个SMP节点也可以运行自己的操作系统、数据库等。但和NUMA不同的是,它不存在异地内存访问的问题。换言之,每个节点内的CPU不能访问另一个节点的内存。节点之间的信息交互是通过节点互联网络实现的,这个过程一般称为数据重分配(Data Redistribution)。但是MPP服务器需要一种复杂的机制来调度和平衡各个节点的负载和并行处理过程。
为什么会有人觉得优化没有必要,因为他们不理解有多耗时
Teach Yourself Programming in Ten Years
Remember that there is a “computer” in “computer science”. Know how long it takes your computer to execute an instruction, fetch a word from memory (with and without a cache miss), read consecutive words from disk, and seek to a new location on disk.
Approximate timing for various operations on a typical PC:
| 耗时 | |
|---|---|
| execute typical instruction | 1/1,000,000,000 sec = 1 nanosec |
| fetch from L1 cache memory | 0.5 nanosec |
| branch misprediction | 5 nanosec |
| fetch from L2 cache memory | 7 nanosec |
| Mutex lock/unlock | 25 nanosec |
| fetch from main memory | 100 nanosec |
| send 2K bytes over 1Gbps network | 20,000 nanosec |
| read 1MB sequentially from memory | 250,000 nanosec |
| fetch from new disk location (seek) | 8,000,000 nanosec |
| read 1MB sequentially from disk | 20,000,000 nanosec |
| send packet US to Europe and back | 150 milliseconds = 150,000,000 nanosec |
| 上下文切换 | 数千个CPU时钟周期,1微秒 |
| 上下文切换 | CPU上下文 | 线程相关结构:栈等 | 进程相关结构:虚拟内存TLB等 |
|---|---|---|---|
| 进程 | 切换 | 切换 | 切换 |
| 进程内线程 | 切换 | 切换 | 不切换 |
| 中断 | 切换 | 用户态不切换,内核态切换 | 用户态不切换,内核态切换 |
| 系统调用 | 切换 | 未切换 | 未切换 |
并行计算能力
SIMD(Single Instruction Multiple Data)
SIMD 表示 利用单条指令执行多条数据,是相对于传统的 SISD(Single Instruction Single Data)来说的。
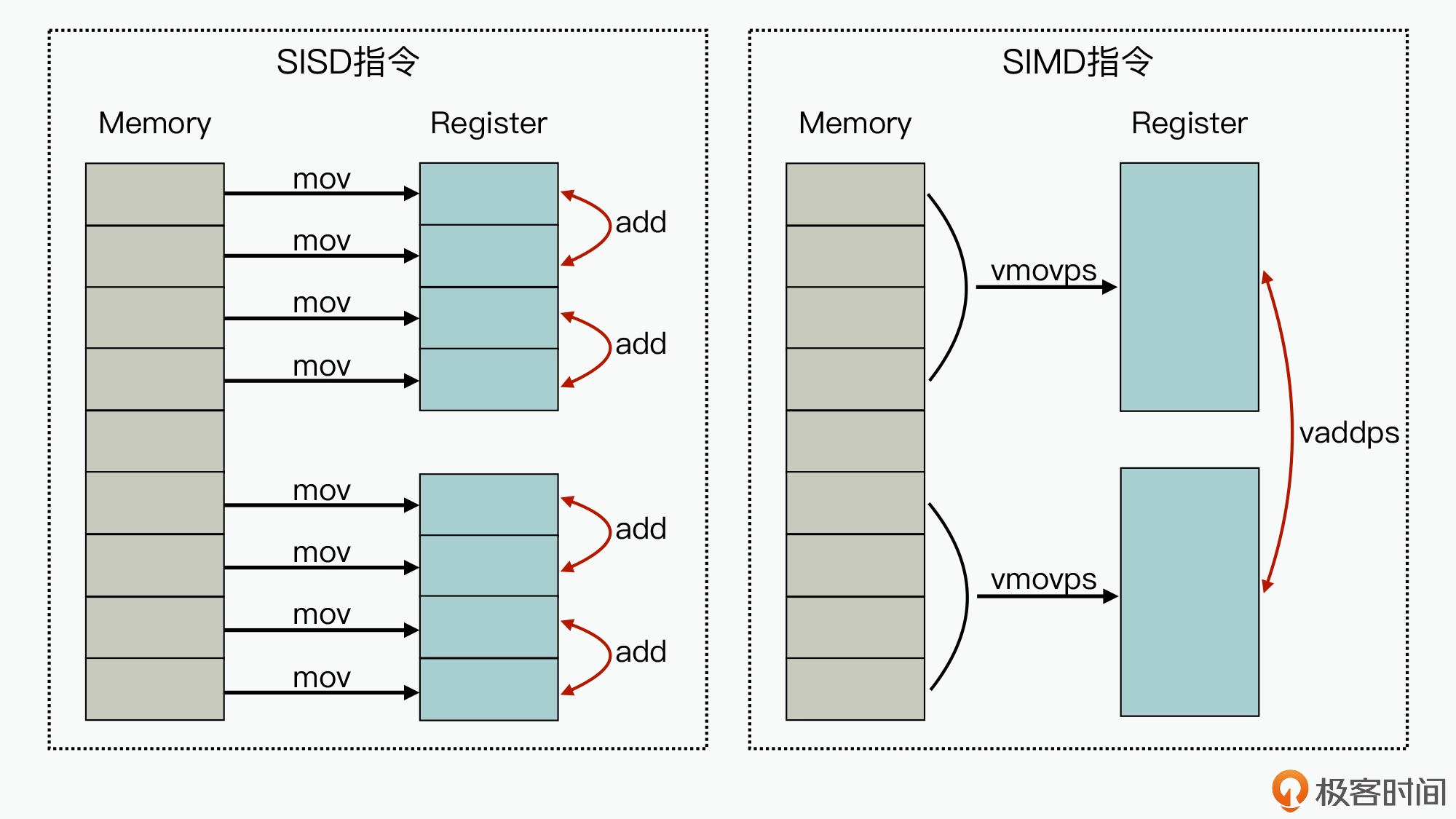
图的左边,代表的是单条指令执行单条数据的实现方式,我们可以看到,针对两组包含 4 个元素的数据,在进行两两相加的操作时,最少需要 12 条指令(8 条 mov 指令,4 条 add 指令)才能完成业务。而图的右边,因为在 CPU 芯片中集成了比较大的寄存器,从而就实现了多条数据导入和多条数据相加操作都可以在一条指令周期内完成,减少了执行 CPU 的指令数,进一步也就提升了计算速度。对于 GPU 来说,也正是因为它可以实现通过单条指令来运行矩阵或向量计算,才可以在数据处理和人工智能领域有比较大的性能优势。
其它
许式伟:引入了输入输出设备的电脑,不再只能做狭义上的计算(也就是数学意义上的计算),如果我们把交互能力也看做一种计算能力的话,电脑理论上能够解决的计算问题变得无所不包。