简介
数据中心日均 CPU 利用率 45% 的运行之道–阿里巴巴规模化混部技术演进
在线资源通常要给一个预留,预留的部分就是浪费的部分,所以要挖掘在线业务占用的资源给离线业务用,但是要注意:资源隔离,在线随时可以抢占离线。
问题
一文看懂业界在离线混部技术而造成资源利用率不高的原因主要有如下几个:
- 粗放的资源评估:研发更关注如何快速稳定的迭代产品需求,所以在服务部署时,一般按照最大流量来估计服务所需资源。但在线服务大都具有明显的潮汐特征,导致大部分时间段资源利用率都很低(10% 以下)从而造成浪费。
- 集群资源整合度不高:服务器的资源占用常常呈现非均衡状态,例如在线服务尤其是调用主链路上的扇出节点业务,高峰期往往呈现出 CPU 和带宽吃紧,但内存绰绰有余的情况。这导致虽然内存有冗余,但依然无法聚合等比例的其它闲置资源去形成有意义的计算实体。
- 业务部署隔离:因为东西部机房成本差异较大和以及容量规划等问题,很多企业会将在线机房、离线机房完全隔离开,这样不同 AZ 甚至不同地域间的在离线作业完全无法融合,资源池也无法互通流转。
技术要求
可观测性体系
操作系统级/资源隔离
容器的本质是一个受限制的进程,进程之间通过 namespace 做隔离,cgroups 做资源限制。在云原生时代,大部分业务资源都是基于容器来隔离和限制,但是在资源超售叠加混部场景下,CPU、内存等方面依然可能存在争抢。
- 例如在 CPU 方面,为了保证在线服务稳定性,普遍做法是进行绑核,将在线服务绑定在某个逻辑核心上避免其他业务占用。但是绑核对于有并行计算要求的服务并不友好,核数直接决定并行效率。
- 在内存方面,离线作业往往会读取大量文件数据,导致操作系统会做 page cache,而原生操作系统对 page cache 的管理是全局的,不是容器维度的。
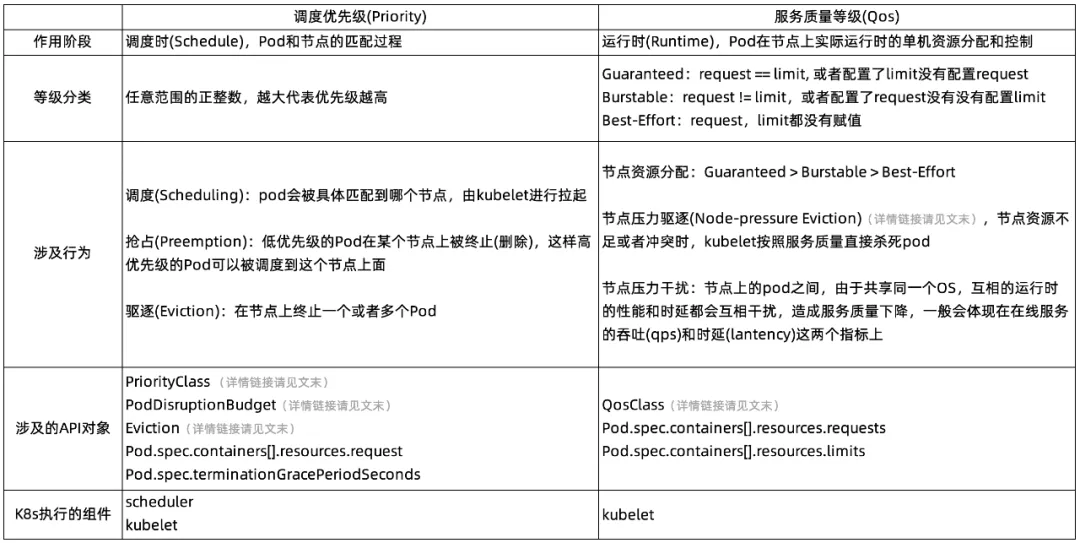
任务冲突时的资源保障:Priority 和 Qos
- CPU 资源质量
- 添加 K8S CPU limit 会降低服务性能? 可以查看container_cpu_cfs_throttled_periods_total 指标
- CPU Burst,例如对于 CPU Limit = 2 的容器,操作系统内核会限制容器在每 100 ms 周期内最多使用 200 ms 的 CPU 时间片,进而导致请求的响应时延(RT)变大。当容器真实 CPU 资源使用小于 cfs_quota 时,内核会将多余的 CPU 时间“存入”到 cfs_burst 中;当容器有突发的 CPU 资源需求,需要使用超出 cfs_quota 的资源时,内核的 CFS 带宽控制器(CFS Bandwidth Controller,简称 BWC) 会允许其消费其之前存到 cfs_burst 的时间片。最终达到的效果是将容器更长时间的平均 CPU 消耗限制在 quota 范围内,允许短时间内的 CPU 使用超过其 quota。
- CPU 拓扑感知调度。在多核节点下,进程在运行过程中经常会被迁移到其不同的核心,,考虑到有些应用的性能对 CPU 上下文切换比较敏感,kubelet 提供了 static 策略,允许 Guarantee 类型 Pod 独占 CPU 核心。CPU 绑核并不是“银弹”,若同一节点内大量 Burstable 类型 Pod 同时开启了拓扑感知调度,CPU 绑核可能会产生重叠,在个别场景下反而会加剧应用间的干扰。因此,拓扑感知调度更适合针对性的开启。
- 针对低优先级离线容器的 CPU 资源压制能力:内核Group Identity,Group Identity 功能可以对每一个容器设置身份标识,以区分容器中的任务优先级,系统内核在调度包含具有身份标识的任务时,会根据不同的优先级做相应处理。比如高优先级任务 有更多资源抢占机会。
- 在 CPU 被持续压制的情况下,BE 任务自身的性能也会受到影响,将其驱逐重调度到其他空闲节点反而可以使任务更快完成。
- 内存资源质量
- 时延敏感型业务(LS)和资源消耗型(BE)任务共同部署时,资源消耗型任务时常会瞬间申请大量的内存,使得系统的空闲内存触及全局最低水位线(global wmark_min),引发系统所有任务进入直接内存回收的慢速路径,进而导致延敏感型业务的性能抖动。
- 后台异步回收,当容器内存使用超过 memory.wmark_ratio 时,内核将自动启用异步内存回收机制,提前于直接内存回收,改善服务的运行质量。
- Kubelet 默认的 CPU 管理策略会通过 Linux 内核的 CFS 带宽控制器(CFS Bandwidth Controller)来控制容器 CPU 资源的使用上限。在多核节点下,进程在运行过程中经常会被迁移到其不同的核心,考虑到有些应用的性能对 CPU 上下文切换比较敏感,Kubelet 还提供了 static 策略,允许 Guaranteed 类型 Pod 独占 CPU 核心。
- 内核 CFS 调度是通过 cfs_period 和 cfs_quota 两个参数来管理容器 CPU 时间片消耗的,cfs_period 一般为固定值 100 ms,cfs_quota 对应容器的 CPU Limit。例如对于一个 CPU Limit = 2 的容器,其 cfs_quota 会被设置为 200ms,表示该容器在每 100ms 的时间周期内最多使用 200ms 的 CPU 时间片,即 2 个 CPU 核心。让应用管理员常常感到疑惑的是,为什么容器的资源利用率并不高,但却频繁出现应用性能下降的问题?从 CPU 资源的角度来分析,问题通常来自于以下两方面:
- 内核在根据 CPU Limit 限制容器资源消耗时产生的 CPU Throttle 问题;由于应用突发性的 CPU 资源需求(如代码逻辑热点、流量突增等),假设每个请求的处理时间均为 60 ms,即使容器在最近整体的 CPU 利用率较低,由于在 100 ms~200 ms 区间内连续处理了4 个请求,将该内核调度周期内的时间片预算(200ms)全部消耗,Thread 2 需要等待下一个周期才能继续将 req 2 处理完成,该请求的响应时延(RT)就会变长。这种情况在应用负载上升时将更容易发生,导致其 RT 的长尾情况将会变得更为严重。若想彻底解决 CPU Throttle,通常需要将 CPU Limit 调大两三倍,有时甚至五到十倍,问题才会得到明显缓解。而为了降低 CPU Limit 超卖过多的风险,还会降低容器的部署密度,进而导致整体资源成本上升。
- 受 CPU 拓扑结构的影响,部分应用对进程在 CPU 间的上下文切换比较敏感,尤其是在发生跨 NUMA 访问时的情况。在 NUMA 架构下,节点中的 CPU 和内存会被切分成了两部分甚至更多(例如图中 Socket0,Socket1),CPU 被允许以不同的速度访问内存的不同部分,当 CPU 跨 Socket 访问另一端内存时,其访存时延相对更高。因此我们需要避免将 CPU 分散绑定到多个 Socket 上,提升内存访问时的本地性。Kubelet 提供的 CPU 管理策略 “static policy”、以及拓扑管理策略 “single-numa-node”,会将容器与 CPU 绑定,可以提升应用负载与 CPU Cache,以及 NUMA 之间的亲和性,但绑核策略并不是“银弹”,某 CPU Limit = 2 的容器,其应用在 100ms 时间点收到了 4 个请求需要处理,在 Kubelet 提供的 static 模式下,容器会被固定在 CPU0 和 CPU1 两个核心,各线程只能排队运行。CPU 绑核解决的是进程在不同 Core,特别是不同 NUMA 间上下文切换带来的性能问题,但解决的同时也损失了资源弹性。
CPU Burst 解决了内核 BWC 调度时针对 CPU Limit 的限流问题,可以有效提升延时敏感型任务的性能表现。但 CPU Burst 本质并不是将资源无中生有地变出来,若容器 CPU 利用率已经很高(例如大于50%),CPU Burst 能起到的优化效果将会受限,此时应该通过 HPA 或 VPA 等手段对应用进行扩容。
调度层
百度混部实践:如何提高 Kubernetes 集群资源利用率?
历经 7 年双 11 实战,阿里巴巴是如何定义云原生混部调度优先级及服务质量的?在这些在线和离线的 Pod 之间,我们就需要用不同的调度优先级和服务质量等级,以满足在线和离线的实际运行需求。
一文看懂业界在离线混部技术目前主要有几种决策方式:
- 整机分时复用:在固定的时间点 (比如凌晨以后) 跑离线作业,白天让出资源给在线服务。这种以时间维度切分的混部方式比较简单易理解,但整体资源利用率提升有限。
- 资源部分共享:将单机的资源整体划分为在线资源、离线资源以及在离线共享资源,各资源之间隔离,提前划分预留。这种从单机资源维度切分的混部方式比分时复用相对更精细一些,但是需要资源规格较大的机器切分才有意义。
- 资源完全共享:通过及时准确的资源预测手段、快速响应资源变化的能力,以及一套可以在资源水位发生变化时的服务保障措施,更高效自动化地实现机器资源复用。资源归属不预设,完全依据实时指标决策。
前一种属于静态决策,相对来说对底层可观测性体系的要求、对调度系统的高可用高性能的要求较低。后两种属于动态决策,在资源利用率的提升上比静态决策更优,但对前述支撑系统要求也更高。
调度执行:由于在线服务和离线作业工作模式的差异,往往需要采用不同的调度器进行调度(比如K8s和Yarn)。混部场景下,在线调度器和离线调度器同时部署在集群中,当资源比较紧张的时候,调度器会发生资源冲突,只能重试,此时调度器的吞吐量和调度性能会受到较大影响,最终影响调度的 SLA。同时,对于大规模批量调度场景,原生的K8s只支持在线服务的调度,从而带来改造成本。
解决方案
- 独占内核 + 物理机 + 静态决策
- 独占内核 + 容器 + 动态决策,比如白天离线作业机器给在线服务使用, 晚上在线服务器转让给离线作业使用,以整机的方式流转。
- 共享内核 + 容器 + 动态决策