简介
预测就是对样本执行前向传播的过程。
- 在线预测。但一般也是批量请求,在推荐场景下,input 一般是
<uid,itemId>,根据uid/itemId 查询各种特征,组成input tensor查询推理服务,output 是uid和itemId 评分,itemId 一般有多个。 - 批量预测
模型保存与加载
模型保存需要把计算图的结构、节点的类型以及变量节点的值从内存写到磁盘文件中,前两者一般保存为xml或json 格式,方便阅读、编辑和可视化,变量节点的值就是矩阵,没有阅读和编辑的需求,使用内存序列化的方式将其保存到一个二进制文件中。
《用python实现深度学习框架》 保存graph 示例
"graph" :[
{
"node_type": "Variable",
"name": "Variable:0",
"parents" : [],
"children": ["MatMul:4"],
"dim": [3,1],
"kargs": {}
},
{
"node_type": "MatMul",
"name": "MatMul:4",
"parents" : ["Variable:0","Variable:2"],
"children": [],
"kargs": {}
}
]
保存变量节点的值,因为计算图中有多个变量节点,因此需要维护节点名称与其序列化值之间的关系。
模型加载: 首先读取xx.json,根据node_type 字段记录的类型,利用Python 的反射机制来实例化相应类型的节点,再利用parents和children 列表中的信息递归构建所有的节点并还原节点间的连接关系,接着读取二进制文件把Variable 的值还原为训练完成时的状态。
模型预测:先找到输入/输出节点,把待预测的样本赋给输入节点,然后调用输出节点的forward 方法执行前向传播,计算出输出节点的值。
serving 服务一个示例c 接口如下
// model_entry: 默认置空
// model_config:从配置文件中读取的json内容,包括模型文件路径、cpu、线程数等配置
// state返回给框架的状态
void* initialize(const char* model_entry, const char* model_config, int* state)
// model_buf:initialize的返回值
// input_data/input_size:输入request的指针以及大小,格式见pb文件, input_size是序列化之后的长度
// output_data/output_size:输出response的指针以及大小,格式见pb文件,output_data是processor分配内存,返回给用户的,output_size指示output_data长度
int process(void* model_buf, const void* input_data, int input_size, void** output_data, int* output_size);
input_data 是 tensor 的 proto 格式表述,假设存在一个tensor[0,0,1,0,1,0],用struct 可以表示为
dtype = int
shape = [6]
intVal = [0,0,1,0,1,0]
以tensorflow 为例
模型文件目录
/tmp/mnist
/1 # 表示模型版本号为1
/saved_model.pb
/variables
/variables.data-00000-of-00001
/variables.index
发布模型
tensoflow_model_server --port=9000 --model_name=mnist --model_base_path=/tmp/mnist
更新线上的模型服务,对于新旧版本的文件处于同一个目录的情况,ModelServer 默认会自动加载新版本的模型
python tensorflow_serving/example/mnist_saved_model.py --training_iteration=10000 --model_version=2 /tmp/mnist
Exporting trained model to /tmp/mnist/2
预估 url http://localhost:9000/v1/tmp/mnist:predict
部署实践
在实践中还要考虑 模型的大小(有的模型几百G),是否动态加载(很多公司没做镜像层面的管理,而是serving 服务直接可以按版本动态加载模型)
基于镜像的模型管理-KubeDL实践
KubeDL 0.4.0 - Kubernetes AI 模型版本管理与追踪
- 从训练到模型。训练完成后将模型文件输出到本地节点的
/models/model-example-v1路径,当顺利运行结束后即触发模型镜像的构建,并自动创建出一个 ModelVersion 对象apiVersion: "training.kubedl.io/v1alpha1" kind: "TFJob" metadata: name: "tf-mnist-estimator" spec: cleanPodPolicy: None # modelVersion defines the location where the model is stored. modelVersion: modelName: mnist-model-demo # The dockerhub repo to push the generated image imageRepo: simoncqk/models storage: localStorage: path: /models/model-example-v1 mountPath: /kubedl-model nodeName: kind-control-plane tfReplicaSpecs: Worker: replicas: 3 -
从模型到推理。Inference Controller 在创建 predictor 时会注入一个 Model Loader,它会拉取承载了模型文件的镜像到本地,并通过容器间共享 Volume 的方式把模型文件挂载到主容器中,实现模型的加载。
apiVersion: serving.kubedl.io/v1alpha1 kind: Inference metadata: name: hello-inference spec: framework: TFServing predictors: - name: model-predictor # model built in previous stage. modelVersion: mnist-model-demo-abcde replicas: 3 template: spec: containers: - name: tensorflow image: tensorflow/serving:1.11.1 command: - /usr/bin/tensorflow_model_server args: - --port=9000 - --rest_api_port=8500 - --model_name=mnist - --model_base_path=/kubedl-model/
seldon
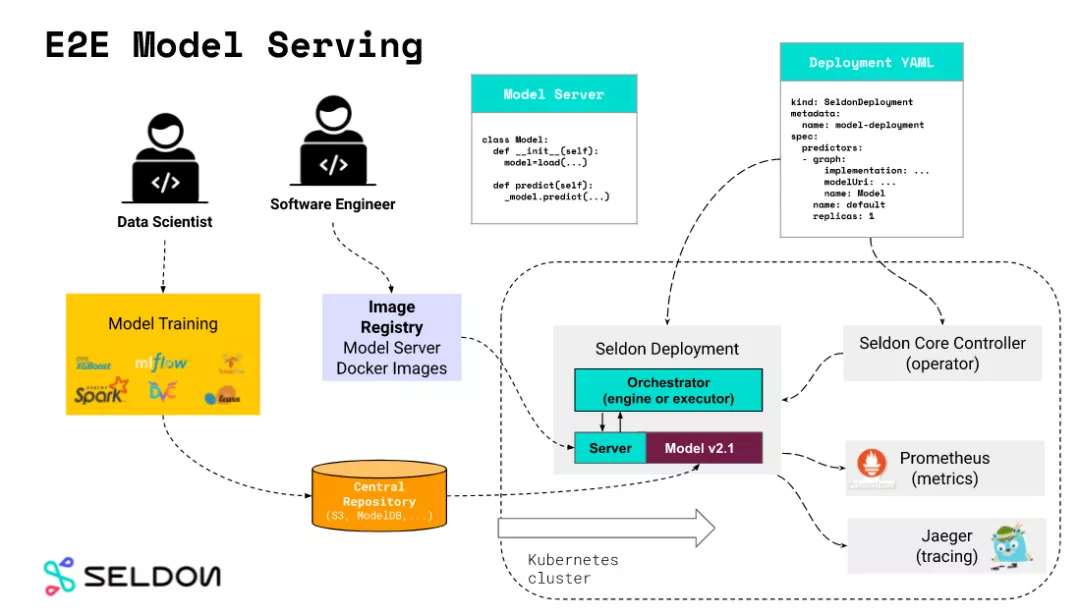
核心概念是 Model Server,Model Servers 通过配置的模型地址,从外部的模型仓库下载模型, seldon 模型预置了较多的开源模型推理服务器, 包含 tfserving , triton 都属于 Reusable Model Servers。
apiVersion: machinelearning.seldon.io/v1alpha2
kind: SeldonDeployment
metadata:
name: tfserving
spec:
name: mnist
predictors:
- graph:
implementation: TENSORFLOW_SERVER
modelUri: gs://seldon-models/tfserving/mnist-model
name: mnist-model
parameters:
- name: signature_name
type: STRING
value: predict_images
- name: model_name
type: STRING
value: mnist-model
name: default
replicas: 1
模型同步
TensorFlow 模型准实时更新上线的设计与实现TensorFlow 原有的模型参数上线流程,需要在训练中将参数保存到文件,再将文件传输到预测服务器,由预测服务器进行加载使用。这个过程流程长,文件传输慢,更新不及时。如果将模型训练时保存的参数和预测服务共用一套,就可几乎完全节省掉参数同步过程的时间消耗。尤其是对于大规模参数的数据传输,节省同步时间带来的效率提升就更大。当然出于数据隔离的考虑,这种方式还需要模型参数的版本管理等辅助支持。
调优
特点
Morphling:云原生部署 AI , 如何把降本做到极致? 专门整了一个论文,推理业务相对于传统服务部署的配置有以下特性:
- 使用昂贵的显卡资源,但显存用量低:GPU 虚拟化与分时复用技术的发展和成熟,让我们有机会在一块 GPU 上同时运行多个推理服务,显著降低成本。与训练任务不同,推理任务是使用训练完善的神经网络模型,将用户输入信息,通过神经网络处理,得到输出,过程中只涉及神经网络的前向传输(Forward Propagation),对显存资源的使用需求较低。相比之下,模型的训练过程,涉及神经网络的反向传输(Backward Propagation),需要存储大量中间结果,对显存的压力要大很多。我们大量的集群数据显示,分配给单个推理任务整张显卡,会造成相当程度的资源浪费。然而如何为推理服务选择合适的 GPU 资源规格,尤其是不可压缩的显存资源,成为一个关键难题。
- 性能的资源瓶颈多样:除了 GPU 资源,推理任务也涉及复杂的数据前处理(将用户输入 处理成符合模型输入的参数),和结果后处理(生成符合用户认知的数据格式)。这些操作通常使用 CPU 进行,模型推理通常使用 GPU 进行。对于不同的服务业务,GPU、CPU 以及其他硬件资源,都可能成为影响服务响应时间的主导因素,从而成为资源瓶颈。
- 容器运行参数的配置,也成为业务部署人员需要调优的一个维度:除了计算资源外,容器运行时参数也会直接影响服务 RT、QPS 等性能,例如容器内服务运行的并发线程数、推理服务的批处理大小(batch processing size)等。
AI 推理任务的优化部署相关主题包括:AI 模型的动态选择、部署实例的动态扩缩容、用户访问的流量调度、GPU 资源的充分利用(例如模型动态加载、批处理大小优化)等。
推理服务规格调优
- 人为经验,倾向于配置较多的资源冗余
- 基于资源历史水位画像,在更通用的超参调优方面,Kubernetes 社区有一些自动化参数推荐的研究和产品,但业界缺少一款直接面向机器学习推理服务的云原生参数配置系统。 Tensorflow 等机器学习框架倾向于占满所有空闲的显存,站在集群管理者的角度,根据显存的历史用量来估计推理业务的资源需求也非常不准确。KubeDL 加入 CNCF Sandbox,加速 AI 产业云原生化 分布式训练尚能大力出奇迹,但推理服务的规格配置却是一个精细活。显存量、 CPU 核数、BatchSize、线程数等变量都可能影响推理服务的质量。纯粹基于资源水位的容量预估无法反映业务的真实资源需求,因为某些引擎如 TensorFlow 会对显存进行预占。理论上存在一个服务质量与资源效能的最优平衡点,但它就像黑暗中的幽灵,明知道它的存在却难以琢磨。
对于 AI 推理任务,我们在 CPU 核数、GPU 显存大小、批处理 batch size、GPU 型号这四个维度(配置项)进行“组合优化”式的超参调优,每个配置项有 5~8 个可选参数。这样,组合情况下的参数搜索空间就高达 700 个以上。基于我们在生产集群的测试经验积累,对于一个 AI 推理容器,每测试一组参数,从拉起服务、压力测试、到数据呈报,需要耗时几分钟。
KubeDL-Morphling 组件实现了推理服务的自动规格调优,通过主动压测的方式,对服务在不同资源配置下进行性能画像,最终给出最合适的容器规格推荐。画像过程高度智能化:为了避免穷举方式的规格点采样,我们采用贝叶斯优化作为画像采样算法的内部核心驱动,通过不断细化拟合函数,以低采样率(<20%)的压测开销,给出接近最优的容器规格推荐结果。
其它
推理服务不仅可以运行在服务端,还可以运行在客户端、浏览器端(比如Tensorflow 提供tensorflow.js)