简介
笔者曾经碰到一个现象, 物理机load average 达到120,第一号进程的%CPU 达到了 1091,比第二名大了50倍,导致整个服务器非常卡,本文尝试分析和解决这个问题
为什么不建议把数据库部署在Docker容器内资源隔离方面,Docker确实不如虚拟机KVM,Docker是利用Cgroup实现资源限制的,只能限制资源消耗的最大值,而不能隔绝其他程序占用自己的资源。如果其他应用过渡占用物理机资源,将会影响容器里MySQL的读写效率。
观察cpu 使用
linux 视角
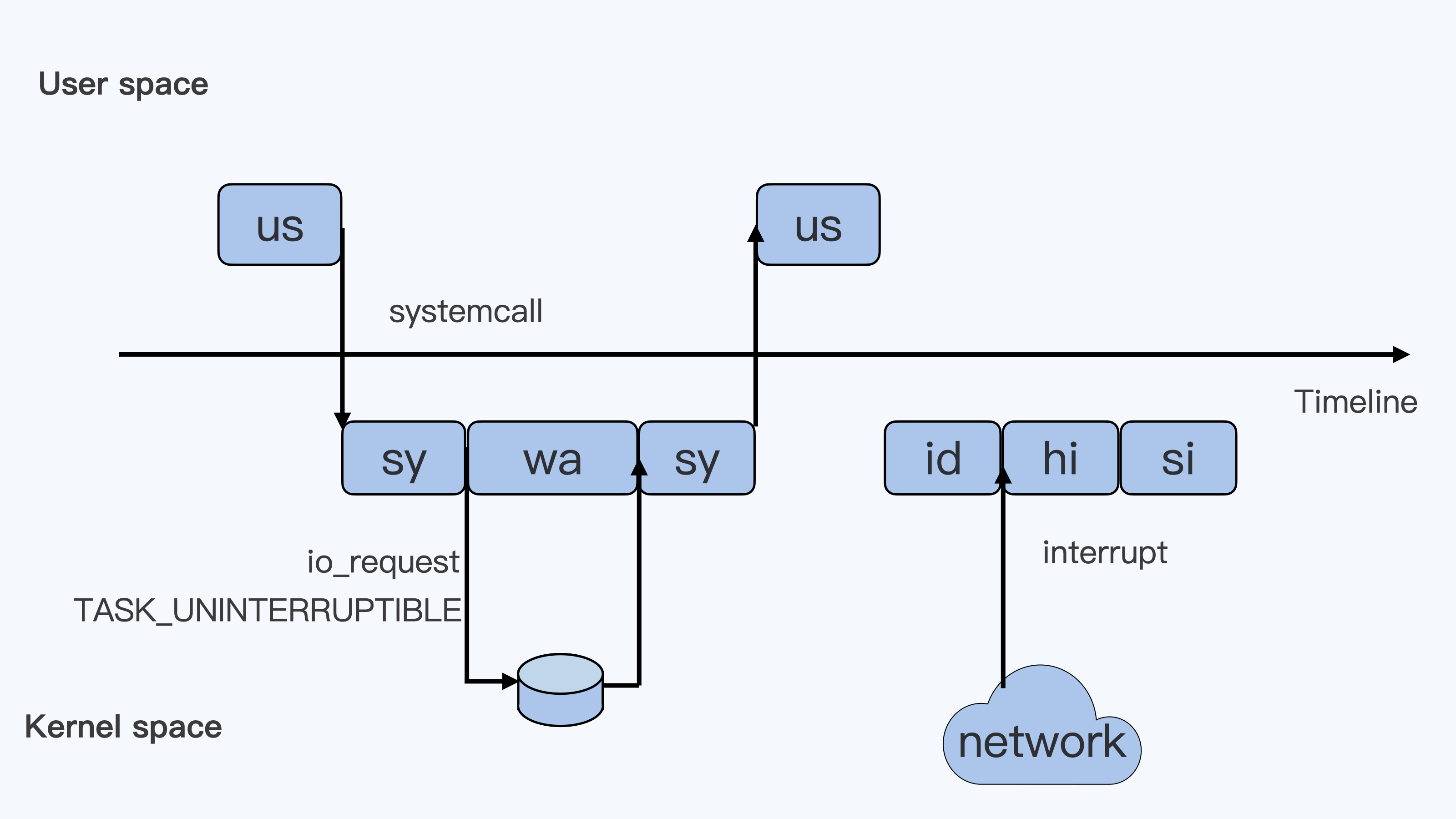
假设只有一个 CPU
- 一个用户程序开始运行了,就对应着第一个”us”框,”us”是”user”的缩写,代表 Linux 的用户态 CPU Usage。普通用户程序代码中,只要不是调用系统调用(System Call),这些代码的指令消耗的 CPU 就都属于”us”。
- 当用户程序代码中调用了系统调用,比如 read() 去读取一个文件,用户进程就会从用户态切换到内核态。内核态 read() 系统调用在读到真正 disk 上的文件前,会进行一些文件系统层的操作,这些代码指令的消耗就属于”sy”。”sy”是 “system”的缩写,代表内核态 CPU 使用。
- 接下来,这个 read() 系统调用会向 Linux 的 Block Layer 发出一个 I/O Request,触发一个真正的磁盘读取操作。这时进程一般会被置为 TASK_UNINTERRUPTIBLE。而 Linux 会把这段时间标示成”wa”,”wa”是”iowait”的缩写,代表等待 I/O 的时间,这里的 I/O 是指 Disk I/O。
- 当磁盘返回数据时,进程在内核态拿到数据,这里仍旧是内核态的 CPU 使用中的”sy”,然后,进程再从内核态切换回用户态,在用户态得到文件数据,”us”。进程在读取数据之后,没事可做就休眠了,”id”是”idle”的缩写,代表系统处于空闲状态。
- 如果这时这台机器在网络收到一个网络数据包,网卡就会发出一个中断(interrupt)。相应地,CPU 会响应中断,然后进入中断服务程序。CPU 就会进入”hi”,”hi”是”hardware irq”的缩写,代表 CPU 处理硬中断的开销。由于我们的中断服务处理需要关闭中断,所以这个硬中断的时间不能太长。
- 但是,发生中断后的工作是必须要完成的,如果这些工作比较耗时那怎么办呢?Linux 中有一个软中断的概念(softirq),它可以完成这些耗时比较长的工作。从网卡收到数据包的大部分工作,都是通过软中断来处理的。那么,CPU 就会进入到第八个框,”si”。这里”si”是”softirq”的缩写,代表 CPU 处理软中断的开销。无论是”hi”还是”si”,它们的 CPU 时间都不会计入进程的 CPU 时间。这是因为本身它们在处理的时候就不属于任何一个进程。wa、hi、si,这些 I/O 或者中断相关的 CPU 使用,CPU Cgroup 不会去做限制
docker 视角
docker stats returns a live data stream for running containers.
docker stats 命令输出
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
4aeb15578094 mesos-19ba2ecd-7a98-4e92-beed-c132b063578d 0.21% 376.4MiB / 1GiB 36.75% 3.65MB / 1.68MB 119kB / 90.1kB 174
77747f26dff4 mesos-e3d34892-8af6-4ab7-a649-0a4b424ccd04 0.31% 752.5MiB / 800MiB 94.06% 11.9MB / 3.06MB 86.1MB / 47MB 132
d64e482d2843 mesos-705b5dc6-7169-42e8-a143-6a7dc2e32600 0.18% 680.5MiB / 800MiB 85.06% 43.1MB / 17.1MB 194MB / 228MB 196
808a4bd888fb mesos-65c9d5a6-3967-4a4a-9834-b83ae8c033be 1.81% 1.45GiB / 2GiB 72.50% 1.32GB / 1.83GB 8.36MB / 19.8MB 2392
- CPU % 体现了 quota/period 值
- MEM USAGE / LIMIT 反映了内存占用
- NET I/O 反映了进出带宽
- BLOCK I/O 反映了磁盘带宽,The amount of data the container has read to and written from block devices on the host ,貌似是一个累计值,但可以部分反映 项目对磁盘的写程度,有助于解决容器狂打日志怎么办?
- PID 反映了对应的进程号,也列出了进程id 与容器id的关系。根据pid 查询容器 id
docker stats --no-stream | grep 1169
具体到语言级,各个语言都有对应的分析工具,比如java 应用,可以进一步使用vjtop等工具分析进程内线程。
Linux的CPU管理——CFS
在 Linux 里面,进程大概可以分成两种:实时进程和 普通进程。每个 CPU 都有自己的 struct rq 结构,其用于描述在此 CPU 上所运行的所有进程,其包括一个实时进程队列 rt_rq 和一个 CFS 运行队列 cfs_rq,在调度时,调度器首先会先去实时进程队列找是否有实时进程需要运行,如果没有才会去 CFS 运行队列找是否有进程需要运行。
cgroup 是 调度器 暴露给外界操作 的接口,对于 进程cpu 相关的资源配置 RT(realtime调度器) 和CFS 均有实现。本文主要讲 CFS,CFS 也是在不断发展的。
CFS 基于虚拟运行时间的调度
What is the concept of vruntime in CFSvruntime is a measure of the “runtime” of the thread - the amount of time it has spent on the processor. The whole point of CFS is to be fair to all; hence, the algo kind of boils down to a simple thing: (among the tasks on a given runqueue) the task with the lowest vruntime is the task that most deserves to run, hence select it as ‘next’. CFS(完全公平调度器)是Linux内核2.6.23版本开始采用的进程调度器,具体的细节蛮复杂的,整体来说是保证每个进程运行的虚拟时间一致, 每次选择vruntime 较少的进程来执行。
vruntime就是根据权重、优先级(留给上层介入的配置)等将实际运行时间标准化。在内核中通过prio_to_weight数组进行nice值和权重的转换。
static const int prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
NICE_0_LOAD = 1024
虚拟运行时间 vruntime += 实际运行时间 delta_exec * NICE_0_LOAD/ 权重
CFS hard limits
对一个进程配置 cpu-shares 并不能绝对限制 进程对cpu 的使用(如果机器很闲,进程的vruntime 虽然很大,但依然可以一直调度执行),也不能预估 进程使用了多少cpu 资源。这对于 桌面用户无所谓,但对于企业用户或者云厂商来说就很关键了。所以CFS 后续加入了 bandwith control。 将 进程的 cpu-period,cpu-quota 数据纳入到调度逻辑中。
- 在操作系统里,cpu.cfs_period_us 的值一般是个固定值, Kubernetes 不会去修改它
cpu.cfs_quota_us/cpu.cfs_period_us的值与 top 命令看到的 进程%CPU是一致的。 PS: 这就把原理与实践串起来了。- 即使 cpu.cfs_quota_us 已经限制了进程 CPU 使用的绝对值,如果两个进程的
cpu.cfs_quota_us/cpu.cfs_period_us和仍然大于了cpu 个数,则cpu.shares可以限定两个进程使用cpu 时间的比例,当系统上 CPU 完全被占满的时候是有用的。
具体逻辑比较复杂,有兴趣可以看CPU bandwidth control for CFS
崩溃,K8s 使用 CPU Limit 后,服务响应变成龟速…
让容器跑得更快:CPU Burst 技术实践 Bandwidth Controller 适用于 CFS 任务,用 period 和 quota 管理 cgroup 的 CPU 时间消耗。若 cgroup 的 period 是 100ms quota 是 50ms,cgroup 的进程每 100ms 周期内最多使用 50ms CPU 时间。当 100ms 周期的 CPU 使用超过 50ms 时进程会被限流,cgroup 的 CPU 使用被限制到 50%。CPU 利用率是一段时间内 CPU 使用的平均,以较粗的粒度统计 CPU 的使用需求,CPU 利用率趋向稳定;当观察的粒度变细,CPU 使用的突发特征更明显。以 1s 粒度和 100ms 粒度同时观测容器负载运行,当观测粒度是 1s 时 CPU 利用率的秒级平均在 250% 左右,而在 Bandwidth Controller 工作的 100ms 级别观测 CPU 利用率的峰值已经突破 400% 。
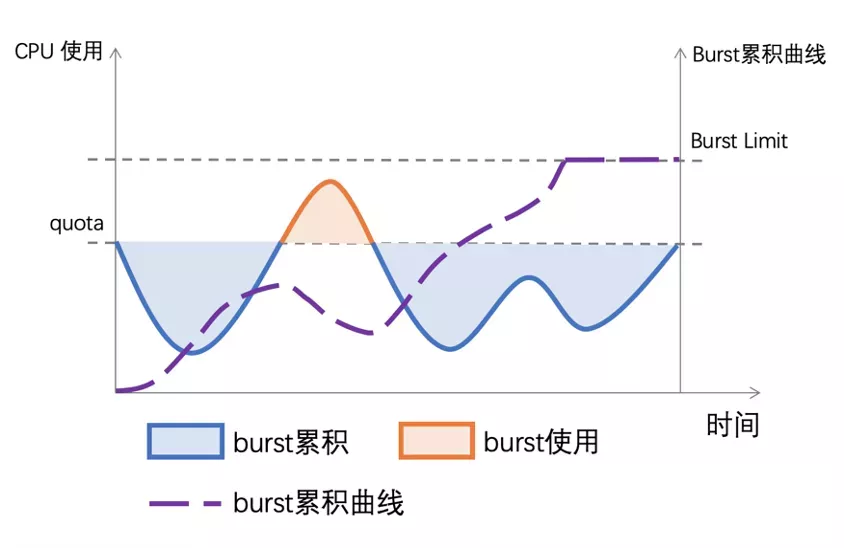
我们用 CPU Burst 技术来满足这种细粒度 CPU 突发需求,在传统的 CPU Bandwidth Controller quota 和 period 基础上引入 burst 的概念。当容器的 CPU 使用低于 quota 时,可用于突发的 burst 资源累积下来;当容器的 CPU 使用超过 quota,允许使用累积的 burst 资源。最终达到的效果是将容器更长时间的平均 CPU 消耗限制在 quota 范围内,允许短时间内的 CPU 使用超过其 quota。如果用 Bandwidth Controller 算法来管理休假,假期管理的周期(period)是一年,一年里假期的额度是 quota ,有了 CPU Burst 技术之后今年修不完的假期可以放到以后来休了。
Linux 进程管理之CFS负载均衡 比想象的还要复杂。
容器 与 CFS
/sys/fs/cgroup/cpu
Kubernetes中的CPU节流:事后分析几乎所有的容器编排器都依赖于内核控制组(cgroup)机制来管理资源约束。在容器编排器中设置硬CPU限制后,内核将使用完全公平调度器(CFS)Cgroup带宽控制来实施这些限制。CFS-Cgroup带宽控制机制使用两个设置来管理CPU分配:配额(quota)和周期(period)。当应用程序在给定时间段内使用完其分配的CPU配额时,此时它将受到CPU节流,直到下一个周期才能被调度。
docker CPU文档By default, each container’s access to the host machine’s CPU cycles is unlimited. You can set various constraints to limit a given container’s access to the host machine’s CPU cycles. Most users use and configure the default CFS scheduler. In Docker 1.13 and higher, you can also configure the realtime scheduler.The CFS is the Linux kernel CPU scheduler for normal Linux processes. Several runtime flags allow you to configure the amount of access to CPU resources your container has. When you use these settings, Docker modifies the settings for the container’s cgroup on the host machine. 默认情况,容器可以任意使用 host 上的cpu cycles,配的不是容器,配的是 CFS,dockers仅仅是帮你设置了下参数而已。
| 示例 | 默认值 | |
|---|---|---|
| –cpuset-cpus | --cpuset-cpus="1,3" |
|
| –cpu-shares | 默认为1024 | 绝对值没有意义,只有和另一个进程对比起来才有意义 |
| –cpu-period | 100ms | Specify the CPU CFS scheduler period,和cpu-quota结合使用 |
| –cpu-quota | Impose a CPU CFS quota on the container,和cpu-period结合使用 | |
| –cpus | 1 | 表示quota/period=1 docker 1.13支持支持,替换cpu-period和cpu-quota |
If you have 1 CPU, each of the following commands guarantees the container at most 50% of the CPU every second.
- Docker 1.13 and higher:
docker run -it --cpus=".5" ubuntu /bin/bash - Docker 1.12 and lower:
docker run -it --cpu-period=100000 --cpu-quota=50000 ubuntu /bin/bash
shares值即CFS中每个进程的(准确的说是调度实体)权重(weight/load),shares的大小决定了在一个CFS调度周期中,进程占用的比例,比如进程A的shares是1024,B的shares是512,假设调度周期为3秒,那么A将只用2秒,B将使用1秒
现在的多核系统中每个核心都有自己的缓存,如果频繁的调度进程在不同的核心上执行势必会带来缓存失效等开销。–cpuset-cpus 可以让容器始终在一个或某几个 CPU 上运行。–cpuset-cpus 选项的一个缺点是必须指定 CPU 在操作系统中的编号,这对于动态调度的环境(无法预测容器会在哪些主机上运行,只能通过程序动态的检测系统中的 CPU 编号,并生成 docker run 命令)会带来一些不便。解决办法 深入理解 Kubernetes CPU Manager
Kubernetes 与 CFS
假设cat /proc/cpuinfo| grep "processor"| wc -l 查看某个node 的逻辑core 数为48,使用kubectl describe node xx查看node cpu情况
Capacity: # 节点的总资源
...
cpu: 48
Allocatable: # 可以分配用来运行pod的
...
cpu: 47
Understanding resource limits in kubernetes: cpu time
resources:
requests:
memory: 50Mi
cpu: 50m
limits:
memory: 100Mi
cpu: 100m
如果不明确标注单位,比如直接写 0.5,默认单位就是Core,即 0.5 个处理器;当然也可以明确使用Millcores为单位,比如写成 500 m,同样也代表 0.5 个处理器,因为 Kubernetes 规定了1 Core = 1000 Millcores。而对于内存来说,它早已经有了广泛使用的计量单位,即 Bytes,如果设置中不明确标注单位,就会默认以 Bytes 计数。为了实际设置的方便,Kubernetes 还支持以Ei、Pi、Ti、Gi、Mi、Ki,以及E、P、T、G、M、K为单位,这两者略微有一点儿差别。这里我就以Mi和M为例,它们分别是Mebibytes与Megabytes的缩写,前者表示 1024×1024 Bytes,后者表示 1000×1000 Bytes。
cpu requests and cpu limits are implemented using two separate control systems.cpu request和limit 是两个cpu cgroup 子系统
| Kubernetes | docker | cpu,cpuacct cgroup |
|---|---|---|
| request=50m | cpu-shares=51 | cpu.shares |
| limit=100m | cpu-period=100000,cpu-quota=10000 | cpu.cfs_period_us,cpu.cfs_quota_us |
request
$ kubectl run limit-test --image=busybox --requests "cpu=50m" --command -- /bin/sh -c "while true; do sleep 2; done"
deployment.apps "limit-test" created
$ docker ps | grep busy | cut -d' ' -f1
f2321226620e
$ docker inspect f2321226620e --format ''
51
Why 51, and not 50? The cpu control group and docker both divide a core into 1024 shares, whereas kubernetes divides it into 1000.
Requests 使用的是 cpu shares 系统,cpu shares 将每个 CPU 核心划分为 1024 个时间片,并保证每个进程将获得固定比例份额的时间片。如果总共有 1024 个时间片,并且两个进程中的每一个都将 cpu.shares 设置为 512,那么它们将分别获得大约一半的 CPU 可用时间。但 cpu shares 系统无法精确控制 CPU 使用率的上限,也就是说如果一个进程没有使用它的这一份,其它进程是可以使用的。
limit
$ kubectl run limit-test --image=busybox --requests "cpu=50m" --limits "cpu=100m" --command -- /bin/sh -c "while true; do
sleep 2; done"
deployment.apps "limit-test" created
$ kubectl get pods limit-test-5b4fb64549-qpd4n -o=jsonpath='{.spec.containers[0].resources}'
map[limits:map[cpu:100m] requests:map[cpu:50m]]
$ docker ps | grep busy | cut -d' ' -f1
f2321226620e
$ docker inspect 472abbce32a5 --format ' '
51 10000 100000
cpu limits 会被带宽控制组设置为 cpu.cfs_period_us 和 cpu.cfs_quota_us 属性的值。
k8s CPU 服务质量等级/Qos
Kubernetes Resources Management – QoS, Quota, and LimitRangeA node can be overcommitted when it has pod scheduled that make no request, or when the sum of limits across all pods on that node exceeds the available machine capacity. In an overcommitted environment, the pods on the node may attempt to use more compute resources than the ones available at any given point in time.When this occurs, the node must give priority to one container over another. Containers that have the lowest priority are terminated/throttle first. The entity used to make this decision is referred as the Quality of Service (QoS) Class.
request 和 limit
- if you set a limit but don’t set a request kubernetes will default the request to the limit(Kubernetes 会将 CPU 的 requests 设置为 与 limits 的值一样). This can be fine if you have very good knowledge of how much cpu time your workload requires.
- How about setting a request with no limit? In this case kubernetes is able to accurately schedule your pod, and the kernel will make sure it gets at least the number of shares asked for, but your process will not be prevented from using more than the amount of cpu requested, which will be stolen from other process’s cpu shares when available.
- Setting neither a request nor a limit is the worst case scenario: the scheduler has no idea what the container needs, and the process’s use of cpu shares is unbounded, which may affect the node adversely.
kubelet 为每个 Pod 设置 Cgroup 的目录结构:首先有一个一级目录叫 kubepod,所有 Pod 的 Cgroup 都会被挂到它下面, Burstable,BestEffort 这两种 Pod 没有直接挂在 kubepod 目录下,而是自己有一个原本是空白的没有值的二级目录。
cgroup
/kubepod
/pod1 // Guaranted pod
/pod2 // Guaranted pod
/Burstable
/pod3
/pod4
/BestEffort
/pod5
/pod6
k8s CPU Qos 问题与解决
百度混部实践:如何提高 Kubernetes 集群资源利用率? 是一篇很好的讲混部的文章 为什么原生 Kubernetes 没办法直接解决资源利用率的问题?
- 资源使用是动态的,而配额是静态限制。在线业务会根据其使用的峰值去预估 Quota(Request 和 Limit),配额申请之后就不能再修改,但资源用量却是动态的,白天和晚上的用量可能都不一样。
- 原生调度器并不感知真实资源的使用情况。对于 Burstable 这种想要超发的业务来说,无法做到合理的配置。
Kubernetes 原本的资源模型存在局限性(引入动态资源视图)。 我们可以基于原生的 QOS 体系做一些不修改原本语义的扩展行为,并且基于质量建立相应的定价体系,通过给出不同质量的资源供给 SLA,来对资源进行差异化定价,从而引导用户更加合理地使用资源。
每个节点运行一个agent(单机引擎),agent根据 Guaranteed-Pod 的真实用量去给 Burstable/BestEffort 目录整体设置了一个值,这个值通过动态计算而来。
Burstable 资源使用 = 单机最大 CPU 用量 - Guaranteed容器用量 - Safety-Margin,BestEffort = 单机最大 CPU 用量 - Guaranteed容器用量 - Burstable容器用量 - Safety-Margin,比如一个pod request=limit=5,日常使用1,当pod 忙起来了,即申请的 Pod 现在要把自己借出去的这部分资源拿回来了,如何处理?此时会通过动态计算缩小 Burstable 和 BestEffort 的这两个框的值,达到一个压制的效果。当资源用量持续上涨时,如果 BestEffort 框整体 CPU 用量小于 1c ,单机引擎会把 BestEffort Pod 全部驱逐掉。当 Guaranteed-Pod 的用量还在持续上涨的时候,就会持续的压低 Burstable 整框 CPU 的 Quota,如果Burstable 框下只有一个 Pod,Request 是 1c,Limit 是 10c,那么单机引擎最低会将 Burstable 整框压制到 1c。换言之,对于 Request,就是说那些用户真实申请了 Quota 的资源,一定会得到得到供给;对于 Limit - Request 这部分资源,单机引擎和调度器会让它尽量能够得到供给;对于 BestEffort,也就是 No Limit 这部分资源,只要单机的波动存在,就存在被优先驱逐的风险. PS: Pod 的Qos 与驱逐策略联系在一起。
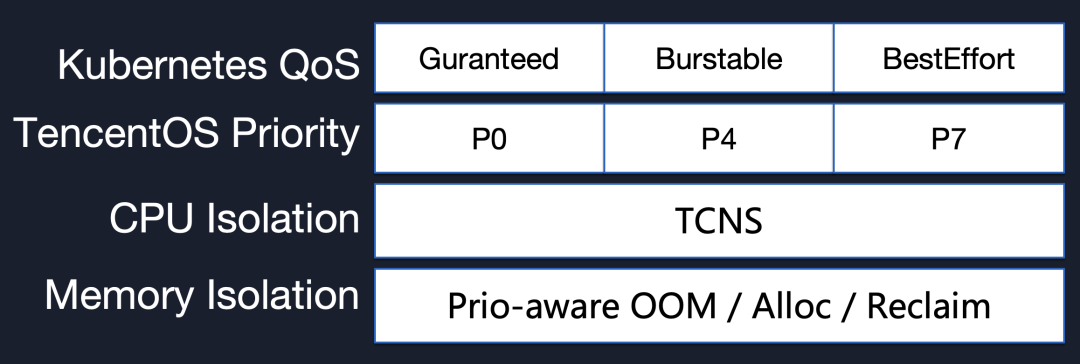
腾讯TencentOS 十年云原生的迭代演进之路通过将 Kubernetes Service QoS Class 与 TencentOS Priority 一一对应,在内核层原生感知优先级(Tencent Could Native Scheduler),在底层提供强隔离机制(Cgroup Priority/CPU QoS/Memory QoS/IO QoS/Net QoS),最大程度保证混部后业务的服务质量。而且这种优先级机制是贯穿在整个 cgroups 子系统中。
谷歌每年节省上亿美金,资源利用率高达60%,用的技术有多厉害!
磁盘
/sys/fs/cgroup/blkio/
- blkio.throttle.read_iops_device, 磁盘读取 IOPS 限制
- blkio.throttle.read_bps_device, 磁盘读取吞吐量限制
- blkio.throttle.write_iops_device, 磁盘写入 IOPS 限制
- blkio.throttle.write_bps_device, 磁盘写入吞吐量限制
OverlayFS 自己没有专门的特性,可以限制文件数据写入量。可以依靠底层文件系统的 Quota 特性(XFS Quota 的 Project 模式)来限制 OverlayFS 的 upperdir 目录的大小,这样就能实现限制容器写磁盘的目的。
在 Cgroup v1 中有 blkio 子系统,它可以来限制磁盘的 I/O。
- 衡量磁盘性能的两个常见的指标 IOPS 和吞吐量(Throughput)。IOPS 是 Input/Output Operations Per Second 的简称,也就是每秒钟磁盘读写的次数,这个数值越大表示性能越好。吞吐量(Throughput)是指每秒钟磁盘中数据的读取量,一般以 MB/s 为单位。这个读取量可以叫作吞吐量,有时候也被称为带宽(Bandwidth)。它们的关系大概是:吞吐量 = 数据块大小 *IOPS。
- Linux 文件 I/O 模式
- Direct I/O
- Buffered I/O, blkio 在 Cgroups v1 里不能限制 Buffered I/O
Cgroup v1 的一个整体结构,每一个子系统都是独立的,资源的限制只能在子系统中发生。比如pid可以分别属于 memory Cgroup 和 blkio Cgroup。但是在 blkio Cgroup 对进程 pid 做磁盘 I/O 做限制的时候,blkio 子系统是不会去关心 pid 用了哪些内存,这些内存是不是属于 Page Cache,而这些 Page Cache 的页面在刷入磁盘的时候,产生的 I/O 也不会被计算到进程 pid 上面。Cgroup v2 相比 Cgroup v1 做的最大的变动就是一个进程属于一个控制组,而每个控制组里可以定义自己需要的多个子系统。Cgroup v2 对进程 pid 的磁盘 I/O 做限制的时候,就可以考虑到进程 pid 写入到 Page Cache 内存的页面了,这样 buffered I/O 的磁盘限速就实现了。但带来的问题是:在对容器做 Memory Cgroup 限制内存大小的时候,如果仅考虑容器中进程实际使用的内存量,未考虑容器中程序 I/O 的量,则写数据到 Page Cache 的时候,需要不断地去释放原有的页面,造成容器中 Buffered I/O write() 不稳定。
网络
Network Namespace 隔离了哪些资源
- 网络设备,比如 lo,eth0 等网络设备。
- IPv4 和 IPv6 协议栈。IP 层以及上面的 TCP 和 UPD 协议栈也是每个 Namespace 独立工作的。它们的相关参数也是每个 Namespace 独立的,这些参数大多数都在
/proc/sys/net/目录下面,同时也包括了 TCP 和 UPD 的 port 资源。 - IP 路由表
- iptables 规则
发现容器网络不通怎么办?容器中继续 ping 外网的 IP ,然后在容器的 eth0 ,容器外的 veth,docker0,宿主机的 eth0 这一条数据包的路径上运行 tcpdump。这样就可以查到,到底在哪个设备接口上没有收到 ping 的 icmp 包。
如何避免系统被应用拖垮
使用 k8s 的cpu limit 机制,在实际落地过程中,容器平台提供几种固定的规格,单个实例的资源配置 能够支持正常跑即可,项目的服务能力通过横向扩展来解决。
以上内容来自对《容器实战高手课》的整理
