简介
你真的懂效率?
- 定义效率
- 度量效率
- 提高效率
为什么要效率以及定义效率
- 瀑布开发的本质问题并不是阶段,而是批量。
- 一个功能有多少价值, 不仅取决于其本身,还取决于什么时候交付。所以要敏捷开发,分feature,以最快的速度交付第一个feature。
-
团队(包括产品也包括开发、业务)什么时候对于产品和项目的知识最充分、最多?项目结束的时候。产品和业务开发本来就是一个探索的过程,开始时一定是最无知的时刻。项目中的大部分决策,是什么时间做出的呢?项目开始的时刻。这里埋藏了一个重大的悖论,我们在最无知的时刻,做出了最重要而且是绝大部分的决策,并把它作为随后执行的依据。对于这一悖论,敏捷的对策还是迭代。
- 敏捷指的是创建一个组织更快(早)的交付价值,和更有效学习和灵活应变的能力。
- 产品开发的最终目的是交付价值,那我们就必须让价值交付的过程顺畅起来,也就是让价值流动顺畅起来。计划、管理、协调活动,以及资源的配置等等,都应该服务于价值的流动。价值流动是目的,资源忙起来不是。
度量效率
我们在阿里内部做团队效能改进时,提出了称之为“2-1-1”的愿景,得到了不少部门的认可。什么是211呢?
- “2”指的是交付周期2周——85%以上的需求可以在2周内交付;它涉及到整个组织各职能,和部门的协调一致,紧密协作。
- 第一个“1”指的是开发周期1周——85%以上的需求可以在1周内开发完成;
- 第二个“1”指的是发布前置时间1小时——提交代码后可以在1小时内完成发布。需要持续交付流水线,产品架构体系和自动化测试、部署等有力保障。
提高效率
路灯下醉汉在找什么东西,很长时间过去了,警察一直看着他,终于忍不住走上前,问道:“你在找啥?”。醉汉说:“找我的钥匙”。警察看了一下钥匙好像不在这,就问:“钥匙是丢在这吗?”醉汉说:“不是”。警察奇怪的问道:“那你为什么在这找?”。“只有这儿能看到啊”
- 现实中我们更多关注资源是否停滞,人是否闲着,但真正的问题并不在这儿。真正的问题是需求的停滞,需求在各个阶段的积压——如分析阶段、测试阶段、发布阶段等等。需求不能顺畅流动才是真正的问题所在,也就是我们所说的关键所在。
-
为什么我们往往对需求的积压很少关注?因为它很难看到,不是光照亮的地方。我们很难觉察(至少很难即时的察觉)。需求的停滞、积压和返工,而那才是改进价值交付的关键所在。
-
要改进端到端的流程,我们必须看到价值端到端的流动过程,在哪里出现了积压和停滞。为此,改进的第一步,就是要让光照亮关键所在——可视化端到端的价值流动过程,基于价值流发现流动过程中的问题。
-
我们还要保障价值流动的过程质量,把交付质量内建到开发过程中,而不是依赖最后环节的测试。为了做到内建质量,我们需要明确定义需求流动的标准
-
潘季驯,他是明朝治理黄河的水利专家,被称为“千古治黄第一人”,治黄河难,难在泥沙不断淤积。清淤是治理黄河的传统办法,问题是清了又会淤,年复一年。嘉靖到万历年间潘季驯四次临危受命治理黄河,取得前所未有的成效,并总结了切实可行的方略,其中最为重要的思想就是“束水攻沙”。什么是“束水攻沙”呢?潘季驯在治理黄河时既没有蛮力清淤,也不是一味地加高、加宽河堤。他反其道而行,收窄河堤——在大堤(称为遥堤)内再修筑一道更窄的堤(称为缕堤),遥堤用以防溃,缕堤用以束水。河堤收窄了,水流的速度就会加快,将沉积的泥沙带走,这就是所谓”束水攻沙”。“束水攻沙”与产品开发有什么关系呢?“束水”加快了水的流速,也带走了泥沙。对应的,产品开发中我们也要限制并行需求的数量,同样是为了缩短需求从开始到完成的平均交付周期——加快流速,并即时发现和处理交付过程中的问题——带走泥沙。
- 以站会为例,团队在站会上,会去审视需求的状态。这里面有两个策略,一种是从左向右审视,还有一个从右往左审视,大家认为哪个合适?对,大家都说从右往左。为什么呢?因为我们应该聚焦于完成而不是开始,我们应该聚焦于尽快的交付,比如测试中的需求是不是有缺陷,并优先解决这些缺陷,好让需求尽快上线;开发中的需求,有没有阻碍,并即时解决这些阻碍,完成它们。
在精益和敏捷开发实施过程中,我们首先做的是可视化价值流动,并以此为基础逐步减小并行需求的数目,力求需求的持续流动——持续小批量的输入、开发、转测试和交付。在减小批量的过程中,问题逐渐暴露。
更重要的是:要让团队看见问题(前提是统一对问题的认识),并且提供合适的路径,一个时间解决一个问题,并且解决问题后要能看到立即的想过。核心有两个,第一:“看见”,它的关键是看见系统,看见价值的端到端流动,以此为基础看到问题和改进机会;第二:“路径”,它的关键是小步快走,但每一步都要有可感知的成果。
小结
- 效率的本质:需求的高速流动
- 需求流动可视化,是否产生积压
- 保障价值流动的过程质量,未达标时不允许流动到下一阶段
阿里云效平台
28位阿里技术专家解密研发效能升级之道(含PDF文件下载) 所有的pdf 文件阅读
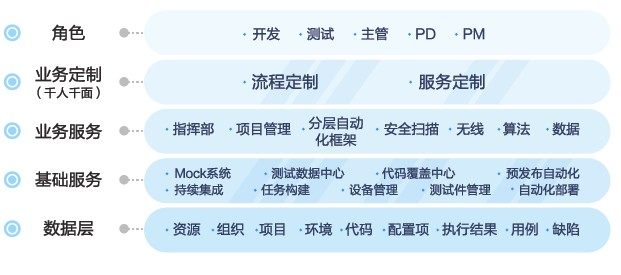

关键字
- 软件生命周期流程 线上化,透明化和自动化。说白了,每一个阶段要先做好,提高单个效率
- 打通。提供沟通效率。
- 借鉴敏捷的研发模式,摸索出了一套行之有效的方法和理念,并沉淀出一整套研发效能平台。
云效,一站式企业协同研发云,源于阿里巴巴多年先进的管理理念和工程实践,提供从“需求->开发->测试->发布->运维->运营”端到端的协同服务和研发工具支撑。
持续交付

主要想表达的是:
- 研发效率里包含什么?
- 每个一个部分如何自动化,提高效率
- 串起来如何自动化,提高效率
承担集团数万应用、研发人员日常工作,阿里持续交付平台的设计、迭代之道
- 平台不能只是工具的堆砌,更需要针对互联网时代的研发模式进行深度思考,不断打磨,将工程师文化和工程师实践不断地融入其中。
- 从需求到代码,从交付到反馈的一站式平台。项目、需求、代码、构建、测试、发布、流水线、舆情反馈等等等等,产品大图基本完备。
-
发展历程
- 自动化,配置、代码、测试、运维的自动化。
- 标准化
- 定制化
- 一站式,一个需求的研发过程中,相关的所有同学要访问几个系统?
- 当交付速度决定市场:我们 CTO 曾说过,研发工具要保障一个 idea 从诞生到上线在 2 周内完成,快速试错,不行就干掉,好了就拉一帮人做大做强。
- 借助中间件全链路 trace 技术,建立测试用例与业务方法的关联关系,当代码变更时推荐需要执行的用例,精准回归,快速反馈。
- 双引擎测试,首先通过 client 对线上请求进行采集,其中包括 request 和 response,以及下游系统,缓存、db 等等的调用链路快照。通过 mq 消息发送给 beta 环境的 client 进行回放。这里就简单进行回放请求就完成了么?显然不是,该工具最核心的是对应用所有的下游依赖进行了隔离和 mock,比如应用发送给 db 一条 sql 查询数据,双引擎测试平台会将这个请求阻断,并返回线上同样查询的快照数据。最终拿到应用的 response 进行实时对比,存储不一致结果。
测试环境
- 资源稳定性
- 部署效率
-
业务稳定性

发布上线完之后我们会去部署一个基础环境,开发环境去调用稳定环境的服务。基础环境部署的是主干代码,也就是线上的代码,会自动部署。

rick 的疑惑:对于一个服务实例,是启动时就知道隔离组,还是后面拖进去的,拖一拖的动作是为了什么?
从中可以看到
- 开发环境不是一个全服务的存在,只有正在测试的服务,最大限度的去复用基础环境下的服务。
- 基础环境的服务 不是想部署就部署的,是你上线后,同样的代码自动部署的
- 源头ip 也可以拖到隔离组,并且对于A调用B来说,怎么路由的,跟A和B在不在一个隔离组没关系,跟源头ip 和 B在不在一个隔离组有关系。
- 可以推断:实例创建的时候便已经指定了隔离组。否则,一个实例创建出来,并且没有分配隔离组的话,便游离在“三界”之外,既不是顶掉原来的服务,也不会有流量进来。
- 在新的理念下,开发/测试环境 不是一个全服务的、服务之间互通的、每个服务都由开发者各自管理的环境。而是一个自动管理的稳定环境 + 服务间隔离的开发环境。从每一个开发者的视角看,他们都拥有稳定的上下游服务。
分支管理策略
- 开始工作前,从主干创建特性分支。
-
通过合并特性分支,形成发布分支。从主干上拉出一条新分支,将所有本次要集成或发布的特性分支依次合并过去,从而得到发布分支。发布分支通常以release/前缀命名。

发布分支的用途可以很灵活
- 基础玩法是将每条发布分支与具体的环境相对应,比如release/test分支对应部署测试环境,release/prod分支对应线上正式环境等等,并与流水线工具相结合,串联各个环境上的代码质量扫描和自动化测试关卡,将产出的部署包直接发布到相应环境上。
- 进阶点的玩法是将一个发布分支对应多个环境,比如把灰度发布和正式发布串在一起,中间加上人工验收的步骤。
- 高级的玩法呢,要是按迭代计划来关联特性分支,创建出以迭代演进的固定发布分支,再把一系列环境都串在这个发布分支的流水线上,就有点经典持续集成流水线的味道了。
当然,这些花哨的高级玩法是我臆想的,阿里的发布分支一般都还是比较中规中矩。
- 发布到线上正式环境后,合并相应的发布分支到主干,在主干添加标签,同时删除该发布分支关联的特性分支。
由于测试环境、集成环境、预发布环境、灰度环境和线上正式环境等发布流程通常是顺序进行的,在流程上可以要求只有通过前一环境验证的特性,才能传递到下一个环境做部署,形成漏斗形的特性发布流。
AoneFlow 的技术门槛以及阿里内部的应对之道
- 除了开发流程和代码分支的管理方式以外,还包括日常开发中的一些约定俗成的规约。
-
工具可以使得团队协作更加平滑,在阿里内部,使用 AoneFlow 流程的团队基本上不用自己运行 Git 来处理分支的事情
- 由于是内部工具,平台的功能高度内聚。对于项目而言,从提出原始需求,将需求拆分为任务,然后根据任务在线创建特性分支,再聚合生成发布分支,同时根据模板自动创建测试环境,直到后期的运维保障都可以一站式的搞定。
- 平台对于 AoneFlow,向前做到了将特性分支和需求项关联起来,确保了特性分支的命名规范性;向后做到了将发布分支与部署行为关联起来,确保了各环境版本来源的可靠性。打通了端到端交付的任督二脉。
- 发布分支的流水线。当这些分支被创建或更新时,往往需要伴随其他的一系列行为,比如自动进行集成测试、代码检查与部署
- 平台提供代码仓库各个分支状况的统一展示,包括分支所对应部署环境的机器信息、操作记录等全都一览无余
要点:
- master分支
- 特性分支
- 发布分支,发布分支的操作关联流水线
- 特性分支与发布分支关联,这个关联数据要记录下来