前言
如何组织一个大项目的go 代码
宏观
$tree -F exe-layout
exe-layout
├── cmd/
│ ├── app1/
│ │ └── main.go
│ └── app2/
│ └── main.go
├── go.mod
├── go.sum
├── internal/
│ ├── pkga/
│ │ └── pkg_a.go
│ └── pkgb/
│ └── pkg_b.go
├── pkg1/
│ └── pkg1.go
├── pkg2/
│ └── pkg2.go
└── vendor/
- cmd 目录就是存放项目要编译构建的可执行文件对应的 main 包的源文件
- pkgN 目录,这是一个存放项目自身要使用、同样也是可执行文件对应 main 包所要依赖的库文件,同时这些目录下的包还可以被外部项目引用。有的项目偏好 只有一个pkg 目录。
- 存放仅项目内部引用的 Go 包,这些包无法被项目之外引用;
- 对于以生产可复用库为目的的 Go 项目,可以在 Go 可执行程序项目的基础上去掉 cmd 目录和 vendor 目录。
具体业务
-
可见性和代码划分
- c++ 在类上,即哪怕在同一个代码文件中,仍然无法访问一个类的私有方法
- java 是 类 + 包名
- go 在包上,从其他包中引入的常量、变量、函数、结构体以及接口,都需要加上包的前缀来进行引用。Golang 也可以 dot import 来去掉这个前缀。不幸的是,这个做法并不常规,并且不被建议。
-
假设有一个用户信息管理系统,直观感觉上的分包方式
- 单一package
- 按mvc划分,比如controller包、model包,缺点就是你使用 controller类时 就只得
controller.UserController,controller 重复了 - 按模块划分。比如
user/UserControler.go,user/User.go,缺点就是使用User类时只得user.User
-
按依赖划分,即根包下 定义接口文件
servier.go,包含User和UserController 接口定义,然后定义postgresql/UserService.go或者mysql/UserService.go
github 也有一些demo 项目layout golang-standards/project-layout
并发中处理的内容才是关键,新启一个线程或者协程才是万里长城的第一步,如果其中的业务逻辑有10个分支,还要多次访问数据库并调用远程服务,那无论用什么语言都白搭。所以在业务逻辑复杂的情况下,语言的差异并不会太明显,至少在Java和Go的对比下不明显 Organizing Go source code part 2 未读
import
import(
// 第一部分 标准库
// 第二部分 第三方依赖
// 第三部分 自己的依赖
)
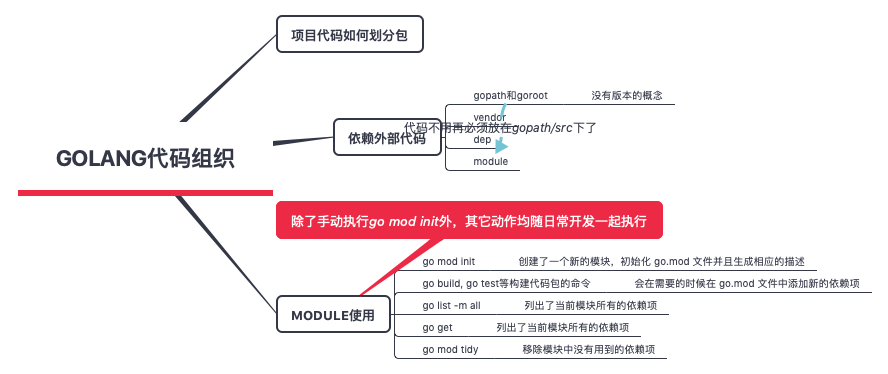
包管理
Golang使用包(package)这种语法元素来组织源码,所有语法可见性均定义在package这个级别,与Java 、python等语言相比,这算不上什么创新,但与C传统的include相比,则是显得“先进”了许多。参见理解Golang包导入
| 编译 | install | |
|---|---|---|
| maven | mvn package/compile | mvn install |
| go | go build | go install |
Go 依赖包管理
| 版本 | ||
|---|---|---|
| vendor机制 | 1.5发布,1.6默认启用,1.7去掉环境变量设置默认开启 | |
| govendor | 1.5以后可用 | 基于 vendor 目录机制的包管理工具 |
| godep | 1.5之前可以用,1.6依赖vendor | |
| Go Modules | 1.11 发布,1.12 增强,1.13正式默认开启 |
最早的GOPATH
对于go来说,其实并不在意你的代码是内部还是外部的,总之都在GOPATH里,任何import包的路径都是从GOPATH开始的;唯一的区别,就是内部依赖的包是开发者自己写的,外部依赖的包是go get下来的。Go 语言原生包管理的缺陷:
- 能拉取源码的平台很有限,绝大多数依赖的是 github.com
- 不能区分版本(对于依赖的同一个包只能从master分支上导入最新的提交,且不能导入包的指定的版本),以至于令开发者以最后一项包名作为版本划分。
- 依赖 列表/关系 无法持久化到本地,需要找出所有依赖包然后一个个 go get
- 只能依赖本地全局仓库(GOPATH/GOROOT),无法将库放置于局部仓库($PROJECT_HOME/vendor)
- 所有的项目都必须在GOPATH/src指向的目录下,或者必须更改GOPATH环境变量所指向的目录。
vendor
vendor属性就是让go编译时,优先从项目源码树根目录下的vendor目录查找代码(可以理解为切了一次GOPATH),如果vendor中有,则不再去GOPATH中去查找。
通过如上vendor解决了部分问题,然而又引起了新的问题:
- vendor目录中依赖包没有版本信息。这样依赖包脱离了版本管理,对于升级、问题追溯,会有点困难。
- 如何方便的得到本项目依赖了哪些包,并方便的将其拷贝到vendor目录下?依靠人工实在不现实。
godep/govendor
在支持vendor机制之后, gopher 们把注意力都集中在如何利用 vendor 解决包依赖问题,从手工添加依赖到 vendor、手工更新依赖,到一众包依赖管理工具的诞生,比如:govendor、glide 以及号称准官方工具的 dep,努力地尝试着按照当今主流思路解决着诸如 “钻石型依赖” 等难题。
godep go build main.go godep中的go命令,就是将原先的go命令加了一层壳,执行godep go的时候,会将当前项目的workspace目录加入GOPATH变量中。
godep save命令将会自动扫描当前目录所属包中import的所有外部依赖库(非系统库),并将所有的依赖库下来下来到当前工程中,产生文件 Godeps/Godeps.json 文件。把所有依赖包代码从GOPATH路径拷贝到Godeps目录下(vendor推出后也改用vendor了)
govendor init生成vendor/vendor.json
govendor add +external更新vendor/vendor.json,并拷贝GOPATH下的代码到vendor目录中。
vendor机制有一个问题:同样的库,同样的版本,就因为在不同的工程里用了,就要在vendor里单独搞一份,不浪费吗?所有这些基于vendor的包管理工具,都会有这个问题。
Go Modules 一统天下
一个 Go Module 是一个 Go 包的集合。module 是有版本的,所以 module 下的包也就有了版本属性。这个 module 与这些包会组成一个独立的版本单元,它们一起打版本、发布和分发。
- repo,仓库,用来管理modules
- modules是打tag的最小单位,也是go mod的最小单位
- packages是被引用的最小单位
一文读懂Go Modules原理 手把手教你如何创建及使用Go module
版本
Go Modules 提供了统一的依赖包管理工具 go mod 基本思想semantic version(社区实际上做不到)
- MAJOR version when you make incompatible API changes(不兼容的修改)
- MINOR version when you add functionality in a backwards compatible manner(特性添加,版本兼容)
- PATCH version when you make backwards compatible bug fixes(bug修复,版本兼容)
依赖包统一收集在 $GOPATH/pkg/mod 中进行集中管理,有点mvn .m2 文件夹的意思。$GOPATH/pkg/mod 中的按版本管理
由 go mod tidy 下载的依赖 module 会被放置在本地的 module 缓存路径下,默认值为 $GOPATH/pkg/mod,Go 1.15 及以后版本可以通过 GOMODCACHE 环境变量,自定义本地 module 的缓存路径,有点maven .m2 文件夹的意思。go build 命令会读取 go.mod 中的依赖及版本信息,并在本地 module 缓存路径下找到对应版本的依赖 module,执行编译和链接。
几项创新
- 语义导入版本:如果同一个包的新旧版本是兼容的,那么它们的包导入路径应该是相同的。如果新旧两个包不兼容,那么我们就应该采用不同的导入路径。将包主版本号引入到包导入路径中,我们可以像下面这样导入 logrus v2.0.0 版本依赖包:
import "github.com/sirupsen/logrus/v2" - 最小版本选择原则:主流编程语言,以及 Go Module 出现之前的很多 Go 包依赖管理工具都会选择依赖项的“最新最大 (Latest Greatest) 版本”,Go 会在该项目依赖项的所有版本中,选出符合项目整体要求的“最小版本”。
如果这个仓库下的布局是这样的:
./srsm
├── go.mod
├── go.sum
├── pkg1/
│ └── pkg1.go
└── pkg2/
└── pkg2.go
module 的使用者可以很轻松地确定 pkg1 和 pkg2 两个包的导入路径,一个是 github.com/bigwhite/srsm/pkg1,另一个则是 github.com/bigwhite/srsm/pkg2。如果 module 演进到了 v2.x.x 版本,那么以 pkg1 包为例,它的包的导入路径就变成了 github.com/bigwhite/srsm/v2/pkg1。
go.mod
$GOPATH/pkg/mod/k8s.io
api@v0.17.0
client-go@v0.17.0
kube-openapi@v0.0.0-20191107075043-30be4d16710a
go.mod
- module:代表go模块名,也即被其它模块引用的名称,位于文件第一行
- require:最小需求列表(依赖模块及其版本信息)
- replace:通过replace将一个模块的地址转换为其它地址(开发者github 上给自己的项目换个地址,删除某个版本等,常事),用于解决某些依赖模块地址发生改变的场景。同时import命令可以无需改变(无侵入)。
- exclude:明确排除一些依赖包中不想导入或者有问题的版本
replace
- replace 只在 main module 里面有效。什么叫 main module? 打个比方,项目 A 的 module 用 replace 替换了本地文件,那么当项目 B 引用项目 A 后,项目 A 的 replace 会失效,此时对 replace 而言,项目 A 就是 main module。因为对于包进行替换后,通常不能保证兼容性,对于一些使用了这个包的第三方module来说可能意味着潜在的缺陷
- replace 指定中需要替换的包及其版本号必须出现在 require 列表中才有效。replace命令只能管理顶层依赖(无法管理间接依赖)
replace (
golang.org/x/crypto v0.0.0-20180820150726-614d502a4dac => github.com/golang/crypto v0.0.0-20180820150726-614d502a4dac
golang.org/x/net v0.0.0-20180821023952-922f4815f713 => github.com/golang/net v0.0.0-20180826012351-8a410e7b638d
golang.org/x/text v0.3.0 => github.com/golang/text v0.3.0
)
replace 的使用场景
- 替换无法下载的包,比如在国内访问golang.org/x的各个包都需要翻墙,你可以在go.mod中使用replace替换成github上对应的库。
- 替换本地自己的包
- 替换 fork 包,有时候我们依赖的第三方库可能有 bug,我们就可以 fork 一份他们的库,然后自己改下,然后通过 replace 将我们 fork 的替换成原来的
冲突解决(还不清晰)
如何欺骗 Go Mod ?
go mod 的智障版本选择
+incompatible :如果 major version 升级至 v2 时,如果该版本没有打算向前兼容,且不想把module path添加版本后缀,则可以在build tag时以 +incompatible 结尾即可,则别的工程引用示例为 require github.com/anqiansong/foo v2.0.0+incompatible
示例
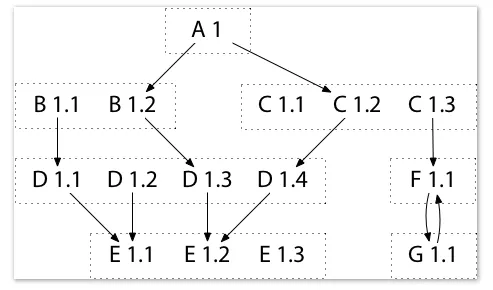
// go.mod
module A1
go 1.14
require (
B1.2
C1.3
D1.4 // indirect
E1.3 // indirect
X v0.0.0-20120604004816-cd527374f1e5
)
- 依赖管理可以归纳为如下四个操作 ,尽量不要手动修改go.mod文件,通过go命令来操作go.mod文件
- 构建项目当前build list
go build - 升级所有依赖模块到它们的最新版本
go get -u - 升级某个依赖模块到指定版本
go get C@1.3 - 将某个依赖模块降级到指定版本
go get D@1.2 - 移除某个依赖
go mod tidy。 仅从源码中删除对依赖项的导入语句不够的
- 构建项目当前build list
- 通过go build编译项目时
- 如果在go.mod文件中指定了直接依赖模块版本,则根据最小版本选择算法会下载对应版本;
- 否则go build会默认自动下载直接依赖模块的最新semantic version
- 若没有semantic version则自动生成标签:
(v0.0.0)-(提交UTC时间戳)-(commit id前12位)作为版本标识
- 出现indirect标记的两种情况:
- A1的某个依赖模块没有使用Go Modules(也即该模块没有go.mod文件),那么必须将该模块的间接依赖记录在A1的需求列表中
- A1对某个间接依赖模块有特殊的版本要求,必须显示指明版本信息(例如上述的D1.4和E1.3),以便Go可以正确构建依赖模块
运行go build或是go mod tidy时golang会自动更新go.mod导致某些修改无效,所以一个包是顶层依赖还是间接依赖,取决于它在本module中是否被直接import,而不是在go.mod文件中是否包含// indirect注释。
其它
- 大多数成功的 Go 应用程序的结构并不能从一个项目复制/粘贴到另一个项目。
- 使用一个远比需要复杂的程序结构,实际上对项目的伤害比帮助更大。
- 对于一个几乎没有 Go 代码经验的人来说,发掘项目的理想结构并不是一个现实的目标。它需要实践、实验和重构来获得正确的结果。