简介
机器学习之 特征工程 是一个系列
特征: 是指数据中抽取出来的对结果预测有用的信息,也就是数据的相关属性。
特征工程:使用专业背景知识和技巧处理数据,使得 特征能在机器学习算法上发挥更好的作用的过程。把原始数据转变为 模型的训练数据的过程。
数据经过整理变成信息,信息能解决某个问题就是知识,知识通过反复实践形成才能,才能融会贯通就是智慧。
Scaling Distributed Machine Learning with the Parameter ServerMachine learning systems are widely used in Web search,spam detection, recommendation systems, computational advertising, and document analysis. These systems automatically learn models from examples, termed training data, and typically consist of three components: feature extraction, the objective function, and learning.Feature extraction processes the raw training data, such as documents, images and user query logs, to obtain feature vectors, where each feature captures an attribute of the training data. Preprocessing can be executed efficiently by existing frameworks such as MapReduce.
特征构建
在原始数据集中的特征的形式不适合直接进行建模时,使用一个或多个原特征构造新的特征 可能会比直接使用原有特征更有效。
- 数据规范化,使不同规格的数据转换到 同一规格。否则,大数值特征会主宰模型训练,这会导致更有意义的小数值特征被忽略
- 归一化
- Z-Score 标准化
- 定量特征二值化,设定一个阈值,大于阈值的赋值为1,小于等于阈值的赋值为0
- 定性特征哑编码
- 分箱,一般在建立分类模型时,需要对连续变量离散化
- 聚合特征构造,对多个特征分组聚合
- 转换特征构造,比如幂变换、log变换、绝对值等
特征提取
将原始数据转换为 一组具有明显 物理意义(比如几何特征、纹理特征)或统计意义的特征
- 降维方面的 PCA、ICA、LDA 等
- 图像方面的SIFT、Gabor、HOG 等
- 文本方面的词袋模型、词嵌入模型等
特征选择
- 过滤式 Filter
- 包裹式 Wrapper
- 嵌入式 embedding
特征准入和淘汰
商业场景中,时时刻刻都会有新的样本产生,新的样本带来新的特征。有一些特征出现频次较低,如果全部加入到模型中,一方面对内存来说是个挑战,另外一方面,低频特征会带来过拟合。因此XDL针对这样的数据特点,提供了一些特征准入机制,包括基于概率进行过滤,布隆过滤器等。比如DeepRec支持了两种特征准入的方式:基于Counter的特征准入和基于Bloom Filter的特征准入:
- 基于Counter的特征准入:基于Counter的准入会记录每个特征在前向中被访问的次数,只有当统计的次出超过准入值的特征才会给分配embedding vector并且在后向中被更新。这种方法的好处子在于会精确的统计每个特征的次数,同时获取频次的查询可以跟查询embedding vector同时完成,因此相比不使用特征准入的时候几乎不会带来额外的时间开销。缺点则是为了减少查询的次数,即使对于不准入的特征,也需要记录对应特征所有的metadata,在准入比例较低的时候相比使用Bloom Filter的方法会有较多额外内存开销。
- 基于Bloom Filter的准入:基于Bloom Filter的准入是基于Counter Bloom Filter实现的,这种方法的优点是在准入比例较低的情况下,可以比较大地减少内存的使用量。缺点是由于需要多次hash与查询,会带来比较明显的时间开销,同时在准入比例较高的情况下,Blomm filter数据结构带来的内存开销也比较大。
有一些特征长时间不更新会失效。为了缓解内存压力,提高模型的时效性,需要淘汰过时的特征,XDL支持算法开发者,通过写用户自定义函数(UDF)的方式,制定淘汰规则。EmbeddingVariable进阶功能:特征淘汰在DeepRec中我们支持了特征淘汰功能,每次存ckpt的时候会触发特征淘汰,目前我们提供了两种特征淘汰的策略:
- 基于global step的特征淘汰功能:第一种方式是根据global step来判断一个特征是否要被淘汰。我们会给每一个特征分配一个时间戳,每次前向该特征被访问时就会用当前的global step更新其时间戳。在保存ckpt的时候判断当前的global step和时间戳之间的差距是否超过一个阈值,如果超过了则将这个特征淘汰(即删除)。这种方法的好处在于查询和更新的开销是比较小的,缺点是需要一个int64的数据来记录metadata,有额外的内存开销。 用户通过配置steps_to_live参数来配置淘汰的阈值大小。
- 基于l2 weight的特征淘汰: 在训练中如果一个特征的embedding值的L2范数越小,则代表这个特征在模型中的贡献越小,因此在存ckpt的时候淘汰淘汰L2范数小于某一阈值的特征。这种方法的好处在于不需要额外的metadata,缺点则是引入了额外的计算开销。用户通过配置l2_weight_threshold来配置淘汰的阈值大小。
#使用global step特征淘汰
evict_opt = tf.GlobalStepEvict(steps_to_live=4000)
#通过get_embedding_variable接口使用
emb_var = tf.get_embedding_variable("var", embedding_dim = 16, ev_option=ev_opt)
特征交叉/Feature crosses
Combining features, better known as feature crosses, enables the model to learn separate weights specifically for whatever that feature combination means.
Introducing TensorFlow Feature Columns——Feature crosses
tf 特征处理 feature column
Introducing TensorFlow Feature Columns 必读文章
起源
TensorFlow Feature Column性能可以这样玩Feature Column是TensorFlow提供的用于处理结构化数据的工具,是将样本特征映射到用于训练模型特征的桥梁。原始的输入数据中既有连续特征也有离散特征,这就需要我给每个特征的定义处理逻辑,来完成原始数据向模型真正用于计算的输入数据的数值化转换。看Google如何实现Wide & Deep模型(2.1)Feature Column本身并不存储数据,而只是封装了一些预处理的逻辑。
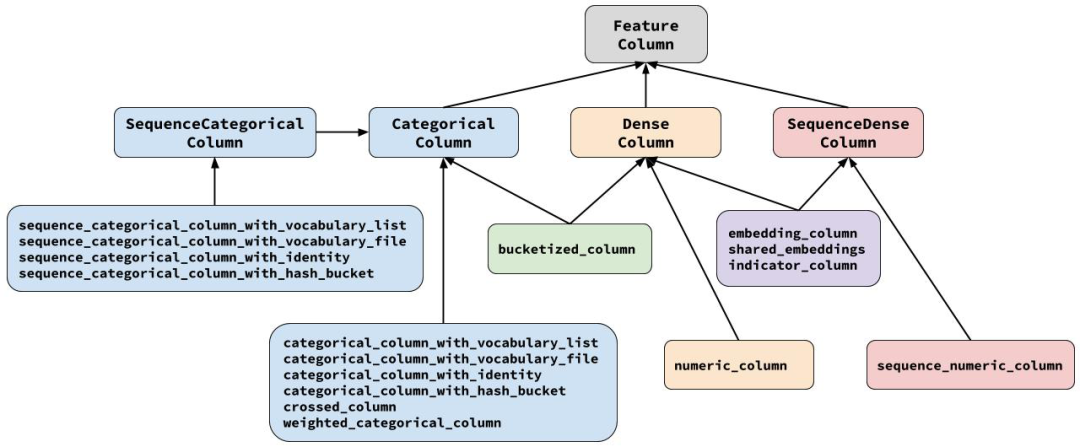
其中只有一个numeric_column是纯粹处理数值特征的,其余的都与处理categorical特征有关,从中可以印证:categorical特征才是推荐、搜索领域的一等公民。
what kind of data can we actually feed into a deep neural network? The answer is, of course, numbers (for example, tf.float32). After all, every neuron in a neural network performs multiplication and addition operations on weights and input data. Real-life input data, however, often contains non-numerical (categorical) data. PS: feature_column 最开始是与Estimator 配合使用的,任何input 都要转换为feature_column传给Estimator, feature columns——a data structure describing the features that an Estimator requires for training and inference.
- Numeric Column
-
Bucketized Column, Often, you don’t want to feed a number directly into the model, but instead split its value into different categories based on numerical ranges. splits a single input number into a four-element vector. ==> 模型变大了,让model 能够学习不同年代的权重(相对只输入一个input year 来说)
Date Range Represented as… < 1960 [1, 0, 0, 0] >= 1960 but < 1980 [0, 1, 0, 0] >= 1980 but < 2000 [0, 0, 1, 0] > 2000 [0, 0, 0, 1] - Categorical identity column, 用一个向量表示一个数字,意图与Bucketized Column 是在一致的,让模型可以学习每一个类别的权重 |类别|数字| Represented as…| |—|—|—| |kitchenware|0| [1, 0, 0, 0]| |electronics|1| [0, 1, 0, 0]| |sport|2| [0, 0, 1, 0]| |history|3| [0, 0, 0, 1]|
- Categorical vocabulary column, We cannot input strings directly to a model. Instead, we must first map strings to numeric or categorical values. Categorical vocabulary columns provide a good way to represent strings as a one-hot vector.
- indicator column, treats each category as an element in a one-hot vector, where the matching category has value 1 and the rest have 0
- embedding column, Instead of representing the data as a one-hot vector of many dimensions, an embedding column represents that data as a lower-dimensional, ordinary vector in which each cell can contain any number, not just 0 or 1. By permitting a richer palette of numbers for every cell
一个脉络就是:除了数值数据,对于分类、 字符串数据,我们不是简单的将其转换为数值型,而是将其转换为了一个向量,目的是尽量学习每一个分类的weight,但是如果某个分类太多,用one-hot 表示太占内存,就需要考虑embedding
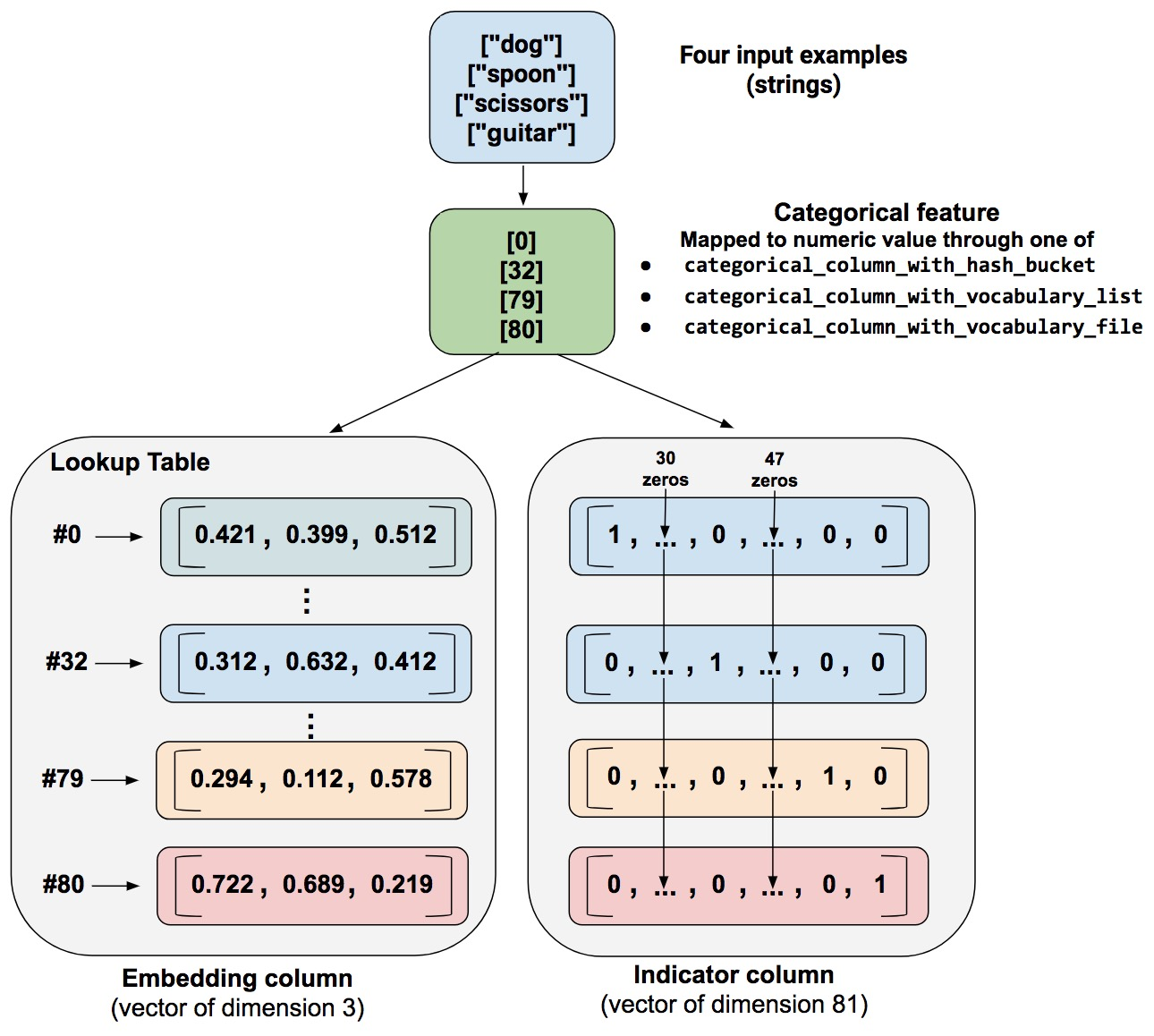
以上图为例,one of the categorical_column_with… functions maps the example string to a numerical categorical value.
- As an indicator column. A function converts each numeric categorical value into an 81-element vector (because our palette consists of 81 words), placing a 1 in the index of the categorical value (0, 32, 79, 80) and a 0 in all the other positions.
- As an embedding column. A function uses the numerical categorical values (0, 32, 79, 80) as indices to a lookup table. Each slot in that lookup table contains a 3-element vector. How do the values in the embeddings vectors magically get assigned? Actually, the assignments happen during training. That is, the model learns the best way to map your input numeric categorical values to the embeddings vector value in order to solve your problem. Embedding columns increase your model’s capabilities, since an embeddings vector learns new relationships between categories from the training data. Why is the embedding vector size 3 in our example? Well, the following “formula” provides a general rule of thumb about the number of embedding dimensions:
embedding_dimensions = number_of_categories**0.25Estimator 方式
花的识别,示例代码
feature_names = ['SepalLength','SepalWidth','PetalLength','PetalWidth']
def my_input_fn(...):
...<code>...
return ({ 'SepalLength':[values], ..<etc>.., 'PetalWidth':[values] },
[IrisFlowerType])
# Create the feature_columns, which specifies the input to our model.All our input features are numeric, so use numeric_column for each one.
feature_columns = [tf.feature_column.numeric_column(k) for k in feature_names]
# Create a deep neural network regression classifier.Use the DNNClassifier pre-made estimator
classifier = tf.estimator.DNNClassifier(
feature_columns=feature_columns, # The input features to our model
hidden_units=[10, 10], # Two layers, each with 10 neurons
n_classes=3,
model_dir=PATH) # Path to where checkpoints etc are stored
# Train our model, use the previously function my_input_fn Input to training is a file with training example Stop training after 8 iterations of train data (epochs)
classifier.train(input_fn=lambda: my_input_fn(FILE_TRAIN, True, 8))
# Evaluate our model using the examples contained in FILE_TEST
# Return value will contain evaluation_metrics such as: loss & average_loss
evaluate_result = estimator.evaluate(input_fn=lambda: my_input_fn(FILE_TEST, False, 4)
心脏病数据集/非 Estimator 方式
对结构化数据进行分类以心脏病数据集为例
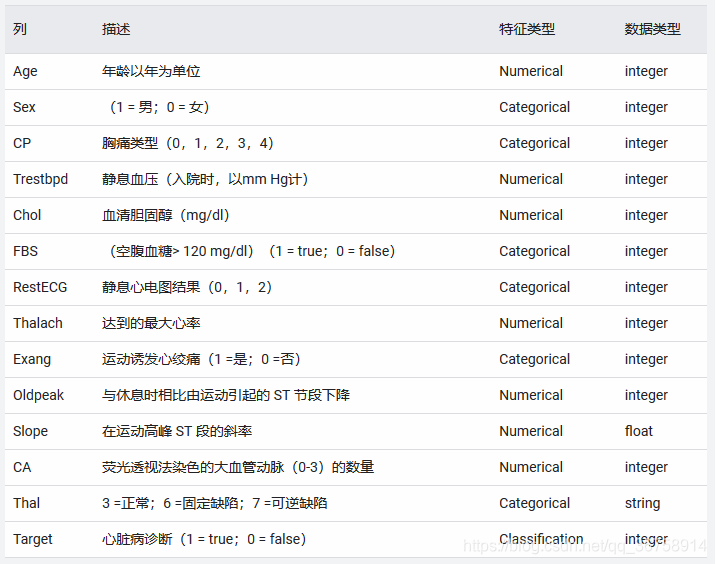
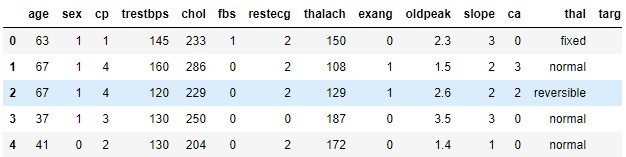
feature_columns = []
# 数值列
for header in ['age', 'trestbps', 'chol', 'thalach', 'oldpeak', 'slope', 'ca']:
feature_columns.append(feature_column.numeric_column(header))
# 分桶列,如果不希望将数字直接输入模型,而是根据数值范围将其值分成不同的类别。考虑代表一个人年龄的原始数据。我们可以用 分桶列(bucketized column)将年龄分成几个分桶(buckets),而不是将年龄表示成数值列。
age = feature_column.numeric_column("age")
age_buckets = feature_column.bucketized_column(age, boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60, 65])
feature_columns.append(age_buckets)
# 分类列,thal 用字符串表示(如 ‘fixed’,‘normal’,或 ‘reversible’)。我们无法直接将字符串提供给模型。相反,我们必须首先将它们映射到数值。分类词汇列(categorical vocabulary columns)提供了一种用 one-hot 向量表示字符串的方法
thal = feature_column.categorical_column_with_vocabulary_list(
'thal', ['fixed', 'normal', 'reversible'])
thal_one_hot = feature_column.indicator_column(thal)
feature_columns.append(thal_one_hot)
# 嵌入列,假设我们不是只有几个可能的字符串,而是每个类别有数千(或更多)值。 由于多种原因,随着类别数量的增加,使用 one-hot 编码训练神经网络变得不可行。我们可以使用嵌入列来克服此限制。嵌入列(embedding column)将数据表示为一个低维度密集向量,而非多维的 one-hot 向量,该低维度密集向量可以包含任何数,而不仅仅是 0 或 1。
thal_embedding = feature_column.embedding_column(thal, dimension=8)
feature_columns.append(thal_embedding)
# 组合列,将多种特征组合到一个特征中,称为特征组合(feature crosses),它让模型能够为每种特征组合学习单独的权重。此处,我们将创建一个 age 和 thal 组合的新特征。
crossed_feature = feature_column.crossed_column([age_buckets, thal], hash_bucket_size=1000)
crossed_feature = feature_column.indicator_column(crossed_feature)
feature_columns.append(crossed_feature)
现在我们已经定义了我们的特征列,我们将使用密集特征(DenseFeatures)层将特征列输入到我们的 Keras 模型中。
feature_layer = tf.keras.layers.DenseFeatures(feature_columns)
model = tf.keras.Sequential([
feature_layer,
layers.Dense(128, activation='relu'),
layers.Dense(128, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy'],run_eagerly=True)
model.fit(train_ds,validation_data=val_ds,epochs=5)
也可以 tensor = tf.feature_column.input_layer(features, feature_columns) 将输入 的features 数据转换为 (input)tensor。
非 Estimator 方式 实现
class _FeatureColumn(object):
# 将inputs 转为 tensor
@abc.abstractmethod
def _transform_feature(self, inputs):
class DenseColumn(FeatureColumn):
def get_dense_tensor(self, transformation_cache, state_manager):
class NumericColumn(DenseColumn,...):
def _transform_feature(self, inputs):
# input_tensor ==> output_tensor
input_tensor = inputs.get(self.key)
return self._transform_input_tensor(input_tensor)
def get_dense_tensor(self, transformation_cache, state_manager):
return transformation_cache.get(self, state_manager)
inputs dataset 带有schema,而每个feature column定义时需要指定一个名字,feature column与input就是通过这个名字联系在一起。
基于 feature_columns 构造 DenseFeatures Layer,反过来说,DenseFeatures Layer 在前向传播时被调用,Layer._call/DenseFeatures.call ==> feature_column.get_dense_tensor ==> feature_column._transform_feature(inputs)。
class DenseFeatures(kfc._BaseFeaturesLayer):
def call(self, features, cols_to_output_tensors=None, training=None):
transformation_cache = fc.FeatureTransformationCache(features)
output_tensors = []
for column in self._feature_columns:
tensor = column.get_dense_tensor(transformation_cache, self._state_manager, training=training)
processed_tensors = self._process_dense_tensor(column, tensor)
output_tensors.append(processed_tensors)
return self._verify_and_concat_tensors(output_tensors)
- 继承关系,DenseFeatures ==> _BaseFeaturesLayer ==> Layer, DenseFeatures 是一个layer,描述了对input dataset 的处理,位于模型的第一层(也叫特征层)
- Generally a single example in training data is described with FeatureColumns. At the first layer of the model, this column-oriented data should be converted to a single
Tensor.
其它
推理性能提升一倍,TensorFlow Feature Column性能优化实践 未读 TensorFlow 指标列,嵌入列 看Google如何实现Wide & Deep模型(2.1)